¿Qué son las pruebas unitarias y la cobertura de código?
En esta entrada se explicará, en un lenguaje accesible incluso para personas que no poseen habilidades de programación, qué son y para qué sirven las «pruebas unitarias» o «unit tests» y los beneficios que podemos obtener si los usamos. También se explicará el término «cobertura de código» o «code coverage» y el uso que se le da.
Desarrollar el código de nuestro proyecto no es la única tarea de la que se debe encargar nuestro equipo de desarrollo. De hecho, hay toda una serie de asuntos que deben ser tratados, pero en esta entrada nos centraremos en las pruebas unitarias o «unit tests».
A medida que el código de nuestro proyecto crece, también crece la posibilidad de introducir, de manera accidental, un fallo en el mismo. Por ese motivo, los proyectos se dividen en muchos bloques más pequeños de código, llamados «funciones».
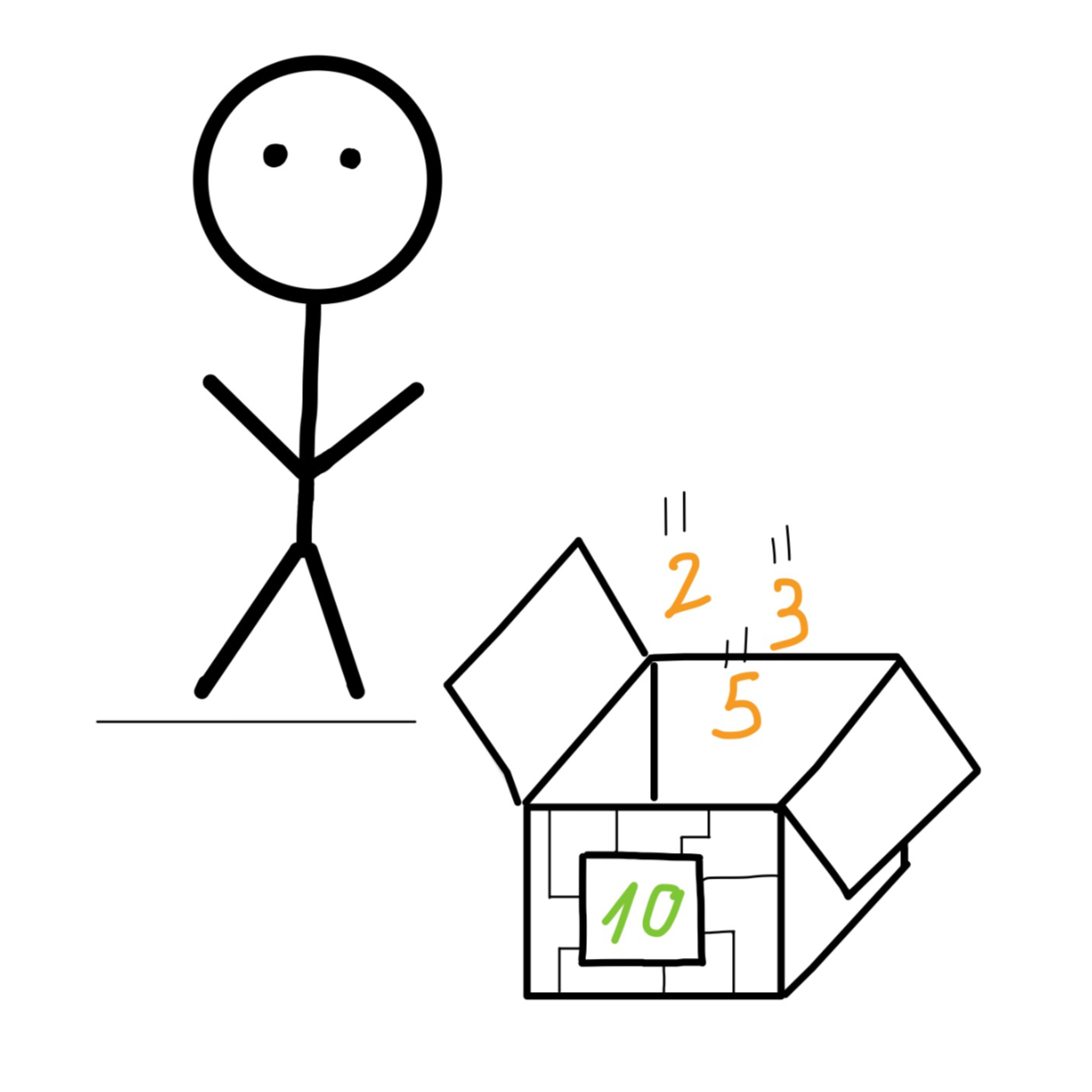
Podemos pensar en estas «funciones» como pequeñas cajas que realizan tareas concretas. Por ejemplo, podemos tener una caja cuyo único objetivo sea sumar los números que pongamos en su interior y darnos el resultado.
Teniendo el código del proyecto dividido en esas pequeñas cajas, podemos encapsular las funcionalidades del mismo y aislar las distintas partes, lo cual a su vez nos permite diagnosticar y resolver los errores con mayor facilidad.
# ¿Qué son?
Los unit test hacen referencia a códigos adicionales que introducimos en nuestro proyecto. A parte de programar el proyecto en sí, se debe dedicar tiempo adicional para programar estos unit tests. Al menos uno por cada «caja».
Pueden programarse una vez finalizado el proyecto, aunque lo más recomendable es hacerlo a la par con el progreso del desarrollo del proyecto en sí. De esta manera los unit test podrán realizar su principal función: detectar fallos en nuestras funciones durante el proceso de desarrollo.
# ¿Para qué sirven?
Podemos verlos como unos robots que nos alertan automáticamente cuando introducimos fallos en nuestro código. A cada «robot» se le dan instrucciones especificas de cómo usar su «caja». En nuestro ejemplo de la caja que suma números, el robot está instruido para introducir en dicha caja una serie de números, cuyo resultado nosotros hemos calculado de antemano, y compararlo con el resultado que le hemos hecho saber.

El objetivo de los unit test es comprobar si nuestras funciones producen los resultados correctos, haciéndolo de manera automatizada y sin que tengamos que intervenir.
# Ejemplo teórico
Pongamos de ejemplo nuestra caja de sumar números. Vamos a suponer que la queremos usar para contabilizar los movimientos de nuestra cuenta bancaria, los cuales obtenemos de un archivo de texto con un número positivo y entero por línea. Es una tarea delicada, así que, antes de nada, calculamos a mano los números de un archivo de muestra y comparamos con el resultado que nos da la caja si introducimos en su interior ese mismo archivo de muestra. Si los números coinciden, significa que nuestra caja suma bien y que podemos usarla en nuestro proyecto.
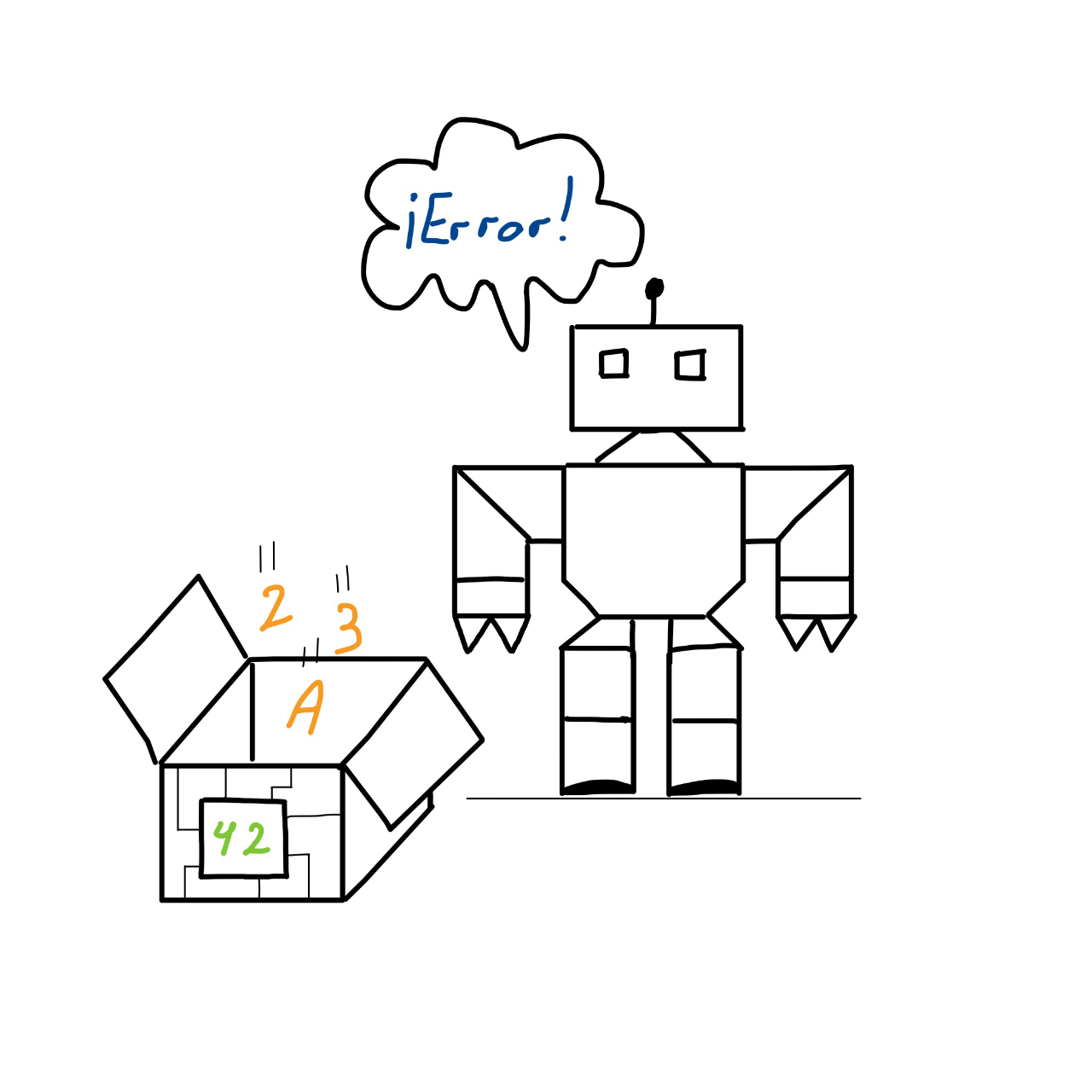
Tras un tiempo, nuestro banco nos informa de un cambio que se aplicará a los archivos: las líneas podrán contener números decimales y números negativos. Nos apresuramos a modificar nuestra caja para hacerla compatible con este cambio, tras lo cual la probamos introduciendo en ella varios números negativos y después varios números decimales. Todo parece funcionar correctamente, así que damos el cambio por bueno y lo integramos en nuestro proyecto en producción.
Empezamos a recibir llamadas y correos de clientes quejándose de errores. ¿Qué ha pasado? Al realizar los cambios, sin querer, hemos introducido un fallo en el código que produce resultados incorrectos al sumar números positivos y enteros. No nos percatamos de este error, porque tras realizar los cambios, probamos la caja únicamente con números negativos y con números decimales. Dimos por buena la funcionalidad de sumar números positivos y enteros, a pesar de haber realizado cambios en el funcionamiento de la caja. Si nuestra caja hubiese tenido unit tests que se ejecutasen antes de integrar dichos cambios en nuestro proyecto, habríamos capturado el error.
# ¿Por qué ocurren fallos como este?
La pregunta es sumamente amplia, así que intentaré enfocarla a nuestro ejemplo. Los distintos lenguajes de programación tienen comportamientos distintos. Algunos se negarán a hacer operaciones matemáticas entre números enteros y decimales (abortando la ejecución del proceso), otros redondearán los números decimales a enteros y luego realizaran las operaciones matemáticas (dándonos un resultado incorrecto), otros no son capaces de operar con números grandes, otros le dan valores distintos a los números dependiendo de si son positivos o negativos, etc… No hay un lenguaje de programación universal que valga para todo, así que sea cual sea el lenguaje de programación que hayamos escogido para nuestro proyecto, siempre nos encontraremos con situaciones como esta.
Precisamente por esa razón, los desarrolladores deben plantear todos los posibles escenarios que podrían darse durante el uso del código que programan. Cuantos más escenarios planteen y cubran, más tiempo requerirá el proceso de desarrollo, pero el resultado final funcionará mejor, detectando una variedad más amplia de errores y manejándolos de la mejor manera posible. Cualquier posible situación, por muy rebuscada que sea y por muy poco probable que sea que se dé, si no se maneja con código, da lugar a fallos.
Otras razones por las que pueden ocurrir fallos de este tipo son:
- Múltiples escenarios - Probar a mano todos y cada uno de los posibles escenarios que se pueden dar, cada vez que hacemos un cambio en una de nuestras cajas, requeriría de un tiempo enorme.
- Factor humano - Incluso aunque aceptásemos el gasto de tiempo que requiere el punto anterior, contamos con la posibilidad de que cometamos un error. Los humanos tendemos a cometer errores, y más si se trata de ejecutar tareas repetitivas.
- Prisas - Programar contando con unos plazos de tiempo de entrega demasiado cortos no es bueno, pero a veces se nos pide sacrificar la calidad de nuestro código en pos de entregar unos resultados en el menor tiempo posible. La reducción en calidad se traduce en código redundante, mal planteado, mal estructurado, etc… Esto a su vez se traduce en más probabilidad de fallos.
- Exceso de seguridad en uno mismo - El exceso de confianza en las habilidades de uno mismo pueden provocar que no creamos necesario probar el código que acabamos de crear o modificar.
- Complejidad - A veces las cajas que hacemos deben realizar tareas extremadamente complejas, es decir, dentro de esas cajas deben de haber múltiples condiciones que comprueben y controlen cada una de las posibles opciones que puedan darse, lo cual a su vez se traduce en un aumento de las probabilidades de cometer un error. En estos casos es buena idea apoyarnos en la cobertura de código.
# ¿Qué es la cobertura de código?
La cobertura de código, o code coverage, es un término que se usa para describir qué tan efectivos son nuestros unit tests. Volvamos, por última vez a nuestro ejemplo de la caja de sumar números positivos, negativos, enteros y decimales. Dicha caja tendrá que tener un «compartimento» para cada uno de los casos que se podrían dar. Es decir, un compartimento para operar con números positivos, otro compartimento para operar con números negativos, (…) y unos cuantos compartimentos especiales, para manejar los casos en los que alguien intente introducir datos incoherentes en la caja (un ejemplo del mundo real podría ser un usuario intentando introducir, en un formulario, su dirección en el campo de número de teléfono).
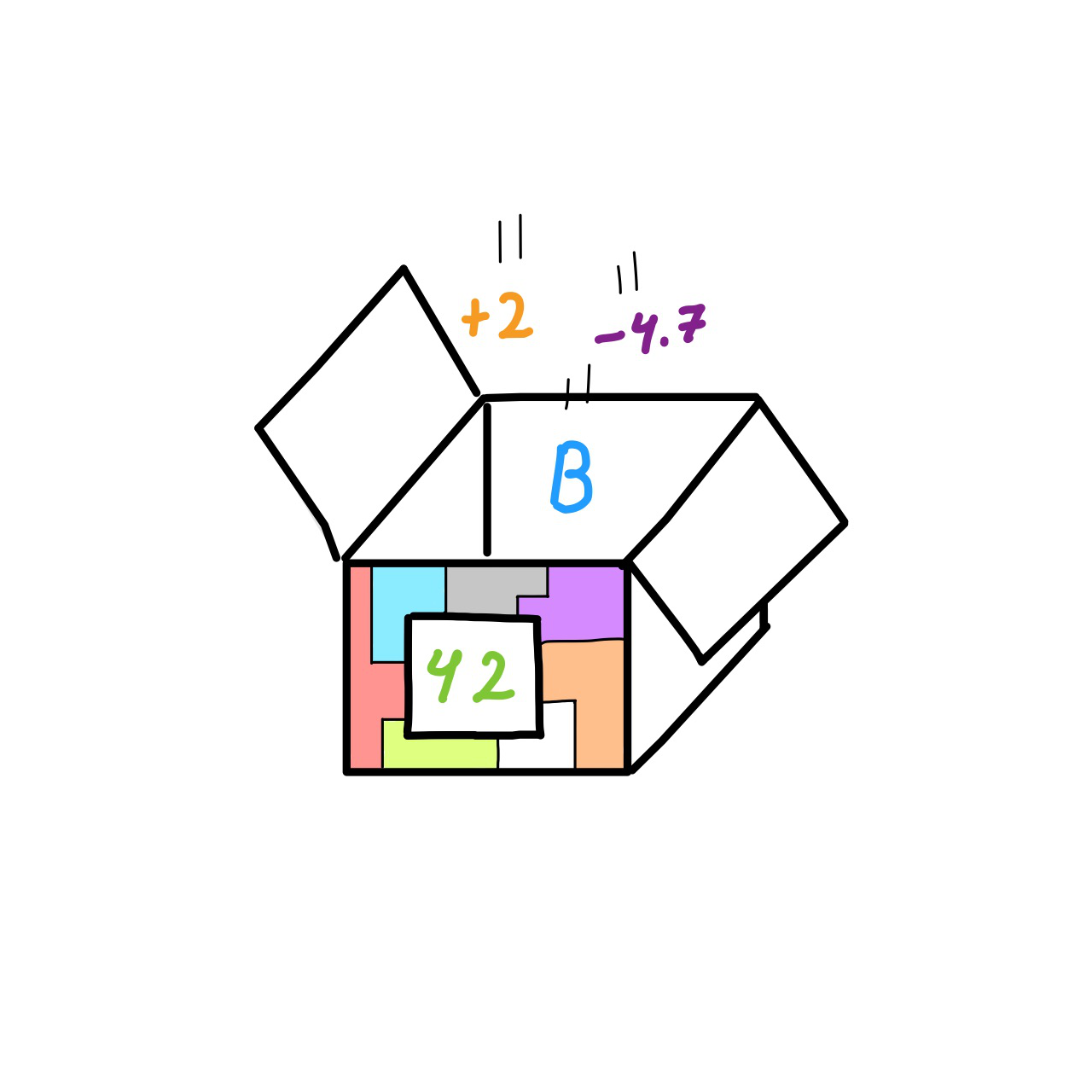
Si quisiéramos asegurarnos de que esta caja funcionase siempre de una manera estable y sin fallos tendríamos que escribir un unit test para cada posible caso. Empezaríamos por el compartimento de números positivos, luego seguiríamos con el compartimento de números negativos y así sucesivamente hasta escribir un unit test para cada compartimento.
Las herramientas de code coverage, que normalmente están integradas en las propias herramientas de unit testing, son capaces de «ver» qué compartimentos hemos probado con nuestros unit test y qué compartimentos han quedado sin ser comprobados. Esto nos permite saber el porcentaje de cobertura del que dispone nuestra caja, y a nivel macroscópico del proyecto, cuántas cajas hemos cubierto con unit tests.
Con estos números podemos hacer estimaciones sobre la fiabilidad y estabilidad de nuestro proyecto en su totalidad y respaldar estas estimaciones con datos precisos.
# Resumiendo
Los unit tests requieren de un tiempo adicional de desarrollo, pero es un coste de tiempo que se paga sólo una vez. En cambio, probar manualmente el código de nuestro proyecto tiene un coste de tiempo que debemos pagar cada vez que realizamos cambios. Los unit test nos sirven como ayudante automatizado para comprobar, en cuestión de segundos, nuestro código en su totalidad. Es decir, a largo plazo, nos compensa el tiempo que hemos invertido en nuestros unit tests.
¡Hola! ¿Te ha gustado el contenido de esta entrada? ¿Te ha aclarado las dudas que tenias sobre el tema? Si crees que podemos ayudarte a resolver los problemas técnicos en tu negocio o si crees que podemos trabajar juntos en tus proyectos o mejorarlos de alguna manera, escríbenos a [email protected].