Integración continua y despliegue continuo
En esta entrada se definirán varios conceptos básicos relacionados con la automatización de las tareas que ejecutamos antes de desplegar nuestro código, así como la automatización de los despliegues en sí. También se describirán las metodologías más comunes que permiten unir estos conceptos y usarlos como un conjunto.
# Integración continua
Durante el proceso de desarrollo de nuestro proyecto, sobre todo cuando en el mismo participa un número elevado de personas, pueden existir una serie de tareas que queramos ejecutar para facilitar el trabajo en equipo y mantener el buen estado del proyecto. Estas tareas pueden ser de cualquier tipo, desde una simple comprobación del código en busca de errores de sintaxis o de formateo incorrecto, hasta la ejecución de pruebas unitarias, pasando por el análisis estático y/o dinámico del código en busca de posibles vulnerabilidades, etc…
Por ejemplo, si ejecutamos las pruebas unitarias antes de que nuestros cambios de código lleguen al repositorio del proyecto, y nos aseguramos de que esas pruebas se han ejecutado bien, podemos tener la certeza de que el proyecto funciona. Esto nos asegura que, si el resto de compañeros deciden descargar dichos cambios, su trabajo no se verá bloqueado por algún fallo que se nos haya podido colar y que haya dejado el proyecto inutilizable. En el mismo escenario, si ejecutamos una herramienta de comprobación de formateo de código y esta no nos permite enviar nuestros cambios de código al repositorio a menos que cumplan los criterios de formateo impuestos en el proyecto, nos aseguraremos de que la totalidad del código cumplirá dichos criterios.
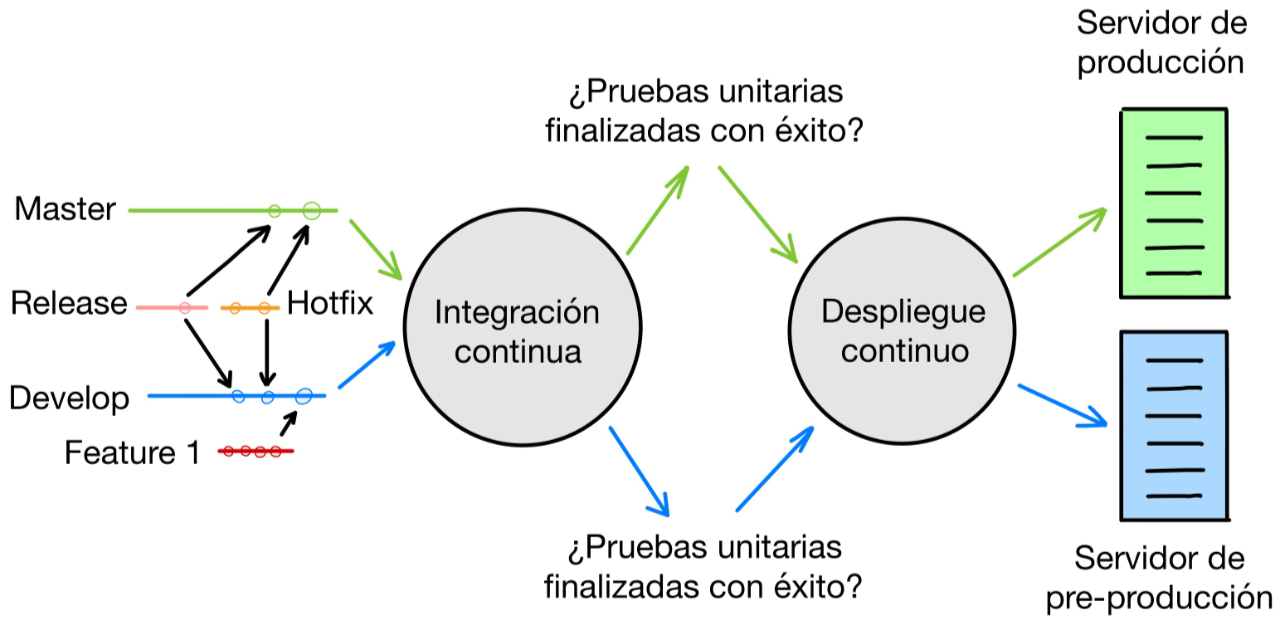
La integración continua es un cúmulo de procesos que se ejecutan cada vez que tiene lugar un cambio en el código y que nos permite llevar una especie de control de calidad sobre los cambios que se producen. La idea de la integración continua es agnóstica a la implementación, es decir, estas tareas pueden ejecutarse en nuestro propio ordenador, en el evento de pre-push de nuestro cliente de Git, pueden ejecutarse en un pipeline en nuestro servidor de Gitlab o pueden ejecutarse en cualquier otro sitio y tras cualquier evento que creamos mas conveniente para nuestro caso de uso.
# Despliegue continuo
Como ya describimos en la entrada sobre el uso de Git Flow, nuestra metodología de trabajo nos permite disponer de una versión de nuestro código que siempre está lista para desplegarse. Partiendo de esa premisa, sería muy cómodo tener una tarea que haga despliegues de manera automatizada cada vez que ocurran cambios en el código en las ramas que hemos definido como «siempre listas para desplegar».
Por ejemplo, aplicando el concepto de despliegue continuo a nuestra rama «develop», podemos ofrecer a nuestro equipo de control de calidad acceso a los últimos cambios que se realizan en el proyecto, sin que tenga que intervenir nadie del equipo de desarrollo o de sistemas. Si aplicamos el despliegue continuo a la rama «master», podemos asegurarnos de que el código que se está ejecutando en producción siempre es el ultimo código que ha alcanzado la rama «master».
Básicamente, la idea del despliegue continuo es mejorar y hacer mas seguro el proceso de despliegue y ahorrar tiempo de trabajo a nuestro equipo. Si hacemos los despliegues de manera manual, siempre habrá una pequeña posibilidad de error humano, ya sea por descuido, por despiste, por hacer el despliegue bajo presión o con prisas. En cambio, si conseguimos automatizar y delegar por completo esta tarea a una máquina, podemos evitar todos esos riesgos. Siguiendo con la comparación, de la primera manera siempre vamos a necesitar del tiempo de al menos una persona, tiempo que se irá en hacer una tarea repetitiva y sin ningún valor para nosotros, mas allá del resultado del despliegue; por el contrario, de la segunda manera esa persona podrá dedicarse a otras tareas.
# CI/CD
Ya entendemos que es la integración continua («CI, continuous integration» en inglés) y el despliegue continuo («CD, continuous deployment» en inglés), así que es hora de ver como usarlas en conjunto.
Como ya hemos visto, la integración continua nos permite proteger el proyecto de nosotros mismos y de los fallos que podríamos introducir. Es decir, podemos tener la certeza de que el código que se encuentra en nuestro repositorio es completamente funcional (según nuestras pruebas unitarias). Por otro lado, el despliegue continuo nos permite desplegar de manera automatizada el código que se encuentra en nuestro repositorio.
Una de las maneras más comunes de unir estos dos conceptos es con la metodología de trabajo Git Flow y se hace de la siguiente manera:
Primero, hacemos obligatoria la ejecución de las pruebas unitarias de nuestro código antes de poder mezclar en las ramas «develop» y «master».
Segundo, ejecutamos un despliegue a nuestros servidores de:
- … pre-producción si alguna rama «feature» o «hotfix» se ha mezclado en «develop» con éxito *
- … producción si hemos mezclado alguna rama «release» o «hotfix» en «master» con éxito *
* con éxito quiere decir que las pruebas unitarias se han ejecutado y no han detectado ningún error.
De esta manera nuestros servidores de pre-producción y producción siempre ejecutarán el código mas reciente que esté disponible en las ramas de «develop» y «master», respectivamente, de nuestro repositorio.
# Consejos adicionales
La integración continua y el despliegue continuo son dos conceptos que pueden convertirse en aliados muy poderosos para nuestro equipo si ponemos los medios necesarios.
Es obvio que nada de esto es posible sin una batería de pruebas sólidas, extensas y consistentes. Si no disponemos de pruebas unitarias de calidad y que cubran la totalidad de nuestro código, lo más probable es que nuestro CI nos de muchos falsos positivos (fallos que no han sido detectados por las pruebas unitarias), que a su vez provocará que se desplieguen fallos en nuestros entornos de pre-producción y producción.
Por ejemplo, si el proceso de integración continua se ejecuta en nuestro servidor de Gitlab en vez de en el ordenador de cada desarrollador de nuestro equipo, estaremos facilitando la tarea de comprobación automatizada de error. Aún más importante, si dicho proceso se ejecuta en pocos minutos, estaremos creando un hábito entre las personas del proyecto de enviar más a menudo sus cambios al repositorio, ya que hacerlo les permitirá obtener una visión rápida sobre la calidad de su trabajo. Esto a su vez hará que la frecuencia de los cambios que se envían al repositorio sea más alta, mientras que el tamaño de cada cambio enviado sea más pequeño. Las tareas de revisión se harán más amenas y fáciles, y por lo tanto, mejora la velocidad con la que se integran dichos cambios en «develop». Nuestro equipo de control de calidad podrá tener un flujo continuo de trabajo, lo cual reducirá los tiempos «muertos» (personas «bloqueadas» a la espera de que otras personas terminen su trabajo).
Por último, cabe decir que no es obligatorio que el despliegue continuo tenga lugar en cuanto un cambio se mezcle en las ramas de «develop» o «master». Existen muchos casos en los que el líder del equipo (o una persona con rol similar) deberá tomar la decisión de dar luz verde al proceso de despliegue en base a más factores. Es decir, el proceso en sí puede estar automatizado (es lo mas recomendable), pero la acción que desencadena el despliegue puede ser humana.
¡Hola! ¿Te ha gustado el contenido de esta entrada? ¿Te ha aclarado las dudas que tenias sobre el tema? Si crees que podemos ayudarte a resolver los problemas técnicos en tu negocio o si crees que podemos trabajar juntos en tus proyectos o mejorarlos de alguna manera, escríbenos a [email protected].