Infraestructura inmutable y despliegue azul/verde
En esta entrada se explicará el significado del término «infraestructura inmutable» y las ventajas que supone aplicar la metodología de despliegue «azul/verde». También se definirá el concepto de tratar a los servidores como «mascotas o ganado».
Cualquiera que haya necesitado desplegar código a un servidor ha tenido que hacer frente a la inevitable situación de tener que actualizar dicho código. Ya sea porque ha surgido un fallo en el código y ha de corregirse, ya sea porque está disponible una nueva característica en una versión más reciente de dicho código, ya sea cualquier otro motivo.
El método más básico, por el que probablemente todo el mundo ha pasado, es el de copiar manualmente archivos de su propio ordenador al servidor en cuestión mediante FTP, SFTP o SCP (usando FileZilla, WinSCP, scp, rsync, etc…). También existen métodos alternativos un poco más avanzados (aunque a efectos prácticos de igual índole), como por ejemplo el uso de Capistrano, Fabric, etc…
# Despliegues
Todas estas herramientas funcionan de la misma manera: establecen una conexión (independientemente del protocolo usado) con el servidor al que queremos desplegar nuestro código y acto seguido copian, desde nuestra maquina al servidor, los archivos en cuestión. Usando cualquiera de estos métodos estamos incurriendo en varios problemas:
Manejo de fallos - No disponemos de una manera simple de evitar los distintos tipos de fallos que puedan surgir durante la operación.
- Fallos de red - Si nuestra conexión queda interrumpida durante el proceso de despliegue, el código que se encuentra en el servidor no tendrá integridad (habrá una mezcla entre los archivos de la versión del código que ya existía en el servidor y los archivos del código que estábamos subiendo) y por lo tanto no funcionará de manera adecuada. Nota: esta situación puede solucionarse subiendo el código a un directorio alternativo y posteriormente, solo tras completar con éxito la subida de todos los archivos, reemplazando el código viejo por el código nuevo.
- Archivos corruptos - Pueden darse muchas razones por las que los archivos que hemos copiado terminen corrompiéndose (fallo de lectura en nuestro propio disco, fallo de escritura en el disco del servidor, fallo temporal de conexión, etc…).
- Archivos incorrectos - Puede darse el caso de que estemos copiando los archivos incorrectos sin darnos cuenta.
Requiere de un salto de fe - No podemos estar seguros de que lo que estamos copiando al servidor va a funcionar. Pueden surgir problemas de todo tipo, desde la incompatibilidad de nuestro código con alguna librería o incluso la versión del sistema operativo, hasta alguna configuración en la que no hemos caído. Por algo se diseñó la excusa «en local me funciona».
Capacidad de reversión - En caso de fallo (ver punto anterior), no disponemos de una manera simple de garantizar la capacidad de revertir la versión del código a otra versión anterior. Podemos intentar volver a desplegar la versión anterior del código, pero nada nos garantiza que no vaya a surgir otro problema. Nota: en algunos casos esta situación puede solucionarse copiando cada versión del código en un directorio nuevo y cambiando la configuración de nuestro servidor para que use ese nuevo directorio. Esto a su vez nos obliga a cambiar la configuración del servidor con cada despliegue y a almacenar en el mismo servidor todas las viejas versiones del código.
Inseguridad por diseño - Todas las personas que estén autorizadas a desplegar código necesitan tener acceso a las credenciales del servidor. Es decir, se crea una situación con múltiples vectores de ataque.
Gestión del servidor - Estamos tratando el servidor como una mascota y no como ganado (punto de inflexión y más detalles sobre esto en el apartado de «Infraestructuras» de esta entrada).
Algunos de estos problemas pueden dejar el servicio en un estado no operativo si ocurren mientras estamos desplegando nuestro código al servidor de producción. Otros pueden provocar situaciones de inseguridad o incertidumbre. Todo esto se traduce en posibles problemas de todo tipo, desde técnicos hasta económicos.
# Infraestructuras
Antes de definir el termino «infraestructura inmutable», vamos a explicar y explorar en más profundidad el trato que le damos a nuestros servidores.
Como se ha mencionado antes, el trato más común que se le da a los servidores es el trato de mascota, es decir, cada servidor tiene su propio nombre, se le aplican tareas de mantenimiento (ya sean manuales o automatizadas), es tratado como una pieza indispensable de nuestra infraestructura y nunca puede apagarse. La alternativa es el trato de los servidores como ganado, es decir, creamos los servidores y aprovisionamos el código que se va a ejecutar dentro de ellos con herramientas de automatización. Si uno de estos servidores deja de comportarse de manera deseada (se vuelve obsoleto o sufre cualquier otro contratiempo), se destruye y se reemplaza - de manera automatizada -, por un nuevo servidor. Así definimos el termino «mascotas vs. ganado».
Tratar a nuestros servidores como mascotas tiene varias desventajas.
- Disminuye la confianza en el servidor - ¿Quién no se ha encontrado en la situación de no querer reiniciar un servidor «por si no vuelve a arrancar»? Es bastante común encontrarse con máquinas con valores de uptime enormes, que inspiran miedo y desconfianza, ya que no se tiene una buena claridad sobre lo que supondría actualizar y reiniciar esa maquina.
- Incrementa el riesgo de rootkit permanente - Es plausible pensar que nuestro servidor puede llegar a ser vulnerado en algún momento (ya sea porque hemos tardado más de la cuenta en aplicar un parche para un agujero de seguridad, ya sea por un fallo en nuestro propio código, etc…). Si nuestro servidor tiene un rol crítico en nuestra infraestructura, reemplazarlo es una tarea casi imposible. Si aceptamos que pueden existir riesgos de infección por rootkit, por definición estamos asumiendo que en algún momento habrá un rootkit permanente en nuestra infraestructura.
- Dificultad para escalar horizontalmente - El escalado vertical (añadir mas recursos al servidor) es fácil, pero el escalado en horizontal requiere de un planteamiento de base muy diferente. Tanto el software que se ejecuta dentro del servidor como el servidor en sí deben estar preparados (ver el post «La aplicación de 12 factores») para poder ser terminados, destruidos y recreados sin complicaciones. Incluso si la primera parte de la condición se cumple, la segunda parte no es posible, por definición, si tratamos nuestro servidor como una mascota.
- Incremento exponencial de la cantidad de trabajo - Mantener como mascota un único servidor es algo fácil, pero ¿y si son 300? A medida que el tamaño de nuestra infraestructura crece, mantener todo de manera artesanal resulta más y más difícil, hasta que llega un momento en el que no es viable.
En cambio, tratar a nuestros servidores como ganado resuelve todas las desventajas enumeradas anteriormente y nos da algunas ventajas:
- Incrementa la confianza en el servidor y en la infraestructura - Teniendo la capacidad de terminar y destruir servidores a nuestro antojo, sin que ello suponga un problema para nuestra infraestructura (ya que nuestro sistema automatizado se encargará de recrear los servidores que nos falten) nos da más seguridad, y sobretodo, nos da la capacidad de poner a prueba nuestra infraestructura, emulando situaciones catastróficas.
- Reduce a cero el riesgo de rootkit permanente - Si somos capaces de destruir nuestros servidores, sin que ello suponga ningún problema para el correcto funcionamiento de nuestro código, podemos hacerlo de manera automatizada en intervalos programados, lo cual dejaría inservible cualquier rootkit.
- Facilita el escalado horizontal - Si nuestro código esta preparado para el escalado horizontal, podremos instruir a nuestro sistema automatizado para crear y mantener operativos en todo momento a más de un servidor, consiguiendo así el escalado horizontal.
- No hay incremento en la cantidad de trabajo - Nuestro sistema automatizado debería poder crear y destruir servidores basándose en el número de servidores activos que hemos especificado que queremos. Nuestra carga de trabajo no debería verse afectada por ese número, sea pequeño o grande.
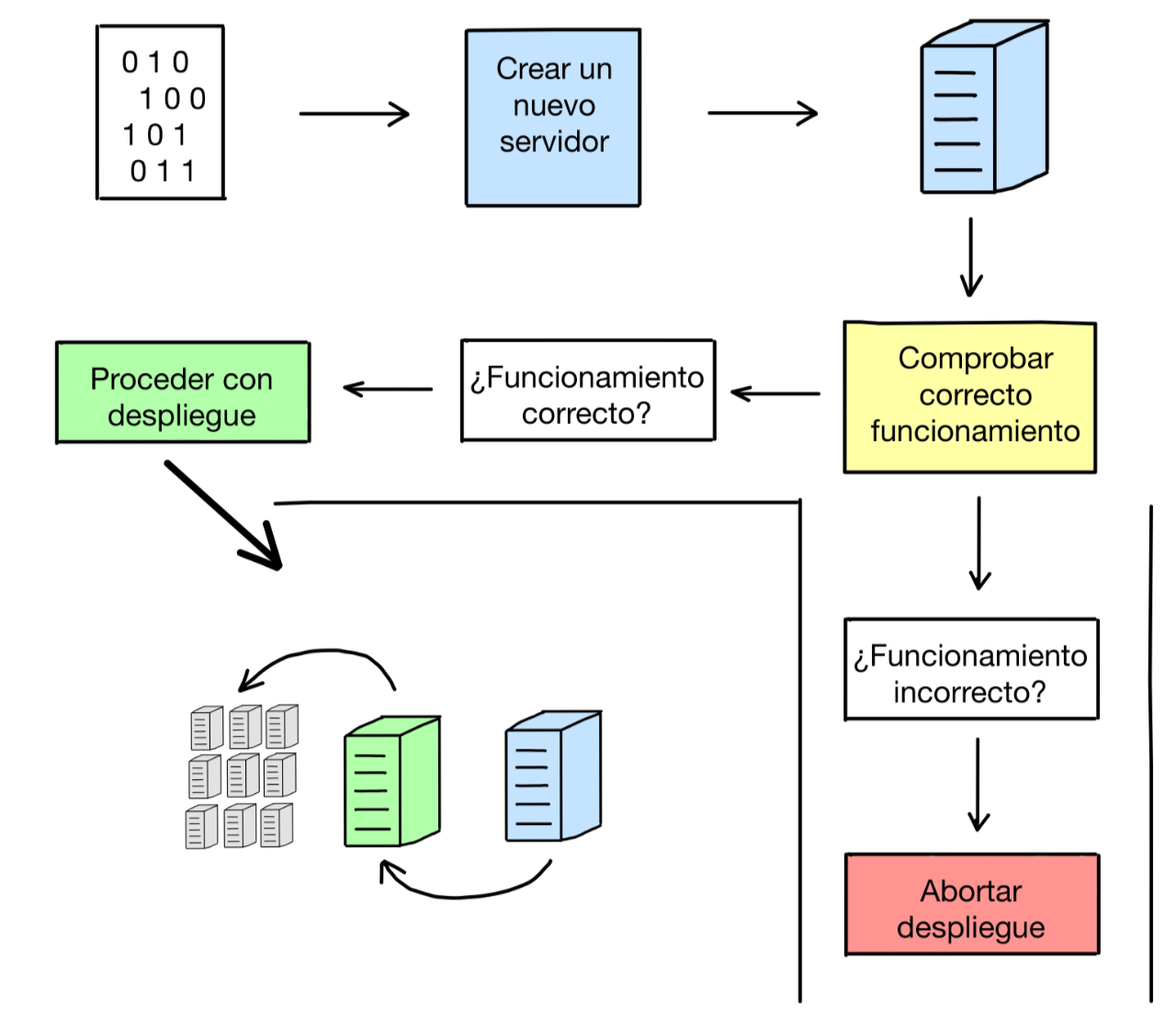
Una vez entendida la diferencia entre los tipos de trato que le damos a nuestros servidores, podemos saltar al siguiente término: «infraestructura inmutable». Nuestra infraestructura se considera inmutable si está formada por componentes que no cambian, sino que son reemplazados por otros componentes. Un ejemplo claro es el problema con el que hemos abierto este post: las actualizaciones de código en nuestros servidores. En una infraestructura inmutable, si quisiéramos desplegar una nueva versión de nuestro código, primero crearíamos un nuevo servidor, aprovisionaríamos nuestro código en él, probaríamos si todo funciona como es debido y, por último, reemplazaríamos el viejo servidor por el que acabamos de crear. A parte de ser un buen ejemplo para explicar el concepto de infraestructura inmutable, este ejemplo define a la perfección el último termino que nos queda por definir en este post: el tipo de despliegue azul/verde.
En los despliegues azul/verde contamos con dos componentes: el componente actual, cuyo estado y funcionamiento es correcto (verde) y el nuevo componente - el recambio -, cuyo estado y funcionamiento aún está por determinar (azul). Tras comprobar (ya sea con pruebas unitarias o de manera manual) que el componente azul cumple los requisitos necesarios para reemplazar al componente verde, se procede al cambio. Después del cambio, el componente verde puede destruirse o guardarse en caso de necesidad de revertir el cambio (algo de lo que ya hablamos en el apartado de «Despliegues», en el punto «capacidad de reversión»), mientras que el componente azul pasa a considerarse el nuevo componente verde.
# Conclusión
Si hacemos nuestra infraestructura inmutable, la tratamos como ganado y usamos la metodología de despliegue azul/verde, podemos:
- Contar con despliegues atómicos, cuyo estado y funcionalidad siempre podremos saber de antemano, aumentando así la estabilidad y la confianza en nuestro sistema.
- Tener disponible un arsenal de servidores (podemos preservar únicamente una copia del disco duro de lo que fue cada servidor en su momento) con versiones viejas de nuestro código, listos para ser arrancados de nuevo en caso de necesidad.
- Disponer de una vía fácil y rápida para probar cambios significativos, por ejemplo, actualizar la versión del sistema operativo de nuestro servidor.
Referencia del termino «mascotas vs ganado» - fue acuñado por Bill Baker durante una presentación sobre escalado horizontal de servidores de SQL, en 2006.
Referencia del termino «azul/verde» - fue acuñado por Dave Farley y Jez Humble en el libro «Continuous Delivery» y fue destacado por Martin Fowler, ambos en 2010.
Referencia del termino «infraestructura inmutable» - fue acuñado por Chad Fowler en su blog, en 2013.
¡Hola! ¿Te ha gustado el contenido de esta entrada? ¿Te ha aclarado las dudas que tenias sobre el tema? Si crees que podemos ayudarte a resolver los problemas técnicos en tu negocio o si crees que podemos trabajar juntos en tus proyectos o mejorarlos de alguna manera, escríbenos a [email protected].