Git Flow como metodología de desarrollo
En esta entrada se describirá una metodología de trabajo que ayuda a organizar los cambios que se aplican sobre el código de un proyecto y facilita el trabajo en equipo. Se parte del supuesto de que se usa Git como sistema de control de versiones y que todo el trabajo se realiza sobre una única rama.
Cuando uno trabaja en un proyecto personal y es el único que hace cambios en el código, todo se hace en serie (un cambio, luego otro, luego otro, etc…). Esto significa que la revisión de los cambios, la estabilidad del repositorio y los conflictos entre los cambios que hagamos dependerá únicamente de nosotros mismos. Esto nos da una serie de ventajas.
- Es muy difícil que se dé la situación de un conflicto entre los cambios
- Llevar el control sobre los distintos cambios que se aplican es fácil
- Tenemos una visión global sobre el estado del proyecto y podemos predecir con facilidad si el repositorio estará en buen estado* o no, por ejemplo, a causa de una gran refactorización.
* Decimos que el repositorio está en buen estado cuando se puede clonar y empezar a trabajar sobre el código sin que surjan errores provocados por cambios realizados a medias.
La cosa cambia radicalmente cuando estamos trabajando en un equipo. Los conflictos de código están a la orden del día y el seguimiento de los cambios que se aplican y sus correspondientes revisiones se hacen más y más difíciles con cada persona adicional que entra en el proyecto. Todo se hace en paralelo, por lo cual los desarrolladores están obligados a elegir entre dos situaciones.
# Situación A
Subir al repositorio únicamente cuando los cambios están terminados. La ventaja de esto es que el código en el repositorio siempre está en un buen estado (con excepciones que se explicarán más adelante). Sin embargo, esto también nos crea varias desventajas. La limitación de subir al repositorio únicamente cuándo hemos completado los cambios que queremos aplicar nos condena a usar un único dispositivo. Por ejemplo, no podremos cambiar entre nuestro ordenador de sobremesa y nuestro portátil, lo cual limita nuestra movilidad.
Nadie puede revisar nuestros parches y darnos su opinión hasta que no los pujemos al repositorio, cosa que no podemos hacer hasta que no estemos seguros de que nuestros parches están bien, y la única manera de saberlo con certeza es mediante la revisión de los mismos por parte de nuestros compañeros. Es decir, tenemos una situación de la pescadilla que se muerde la cola y la única manera de romper el círculo es subiendo al repositorio, arriesgándonos a dejarlo en mal estado o a subir algo que a nuestros compañeros de equipo no les parezca ideal, lo cual invalida la ventaja descrita anteriormente.
# Situación B
Subir al repositorio constantemente. Esto soluciona el problema de la movilidad, pero hace que el repositorio siempre esté en mal estado, ya que todas las personas del equipo subirán constantemente cambios a medias. Esto hará que sea muy difícil trabajar con el código ya que será difícil ejecutarlo, lo cual hará que los desarrolladores prefieran no actualizar sus copias locales contra el repositorio, que a su vez resultará en conflictos más grandes a la hora de sincronizar los cambios.
# Git Flow
Para dar una solución a todos estos problemas, podemos usar las ramas de desarrollo que ofrece Git y la metodología Git Flow, que nos marcará cómo usar dichas ramas de la manera más eficiente.
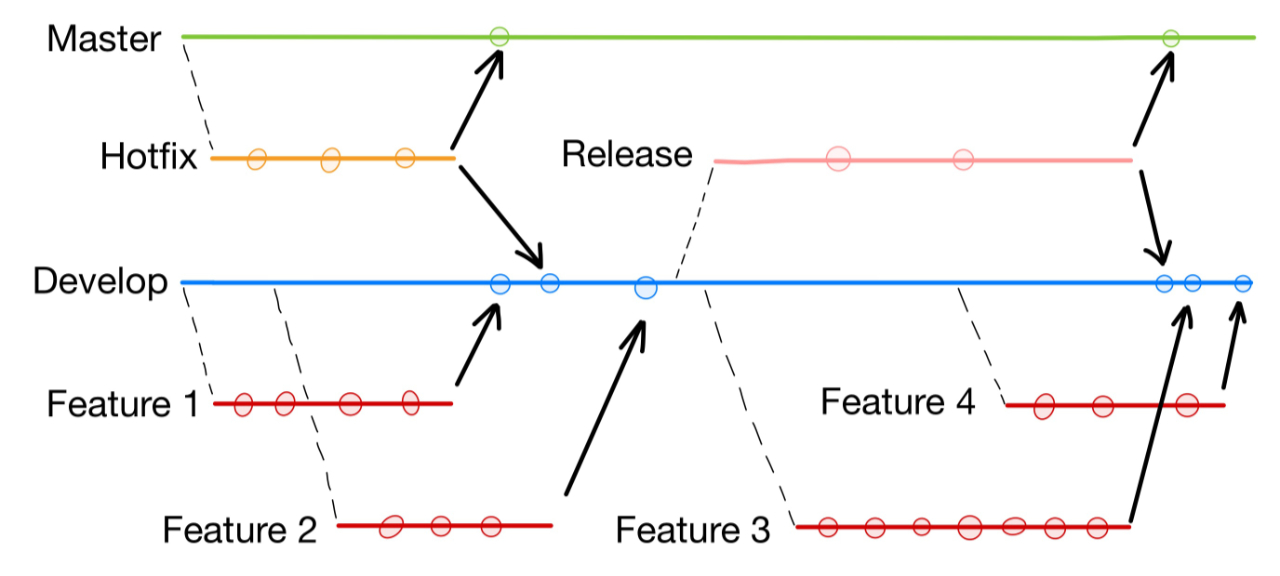
Para empezar, definiremos dos ramas principales: «master» y «develop». Las consideraremos como «versión estable» y «versión pendiente de pruebas» respectivamente.
$ git checkout -b develop master
A continuación, para desarrollar nuevas funcionalidades del código, trabajaremos sobre ramas creadas a partir de la rama «develop» con el prefijo «feature» (por ejemplo, «feature-captcha_en_registro»). Subiremos nuestros cambios únicamente a esa rama, permitiendo así que el resto del equipo pueda revisarlos o mandarnos parches, si hemos pedido ayuda. Si el feedback recibido sobre nuestros parches es positivo, mezclaremos nuestra rama en «develop».
$ git checkout -b feature-captcha_en_registro develop
$
# Aquí es donde trabajaremos sobre el código y realizaremos los cambios deseados, haciendo uno o múltiples "git commit".
$
$ git push origin feature-captcha_en_registro
$
# Podemos hacer "git pull" en caso de haber recibido parches por parte de compañeros del equipo.
$
$ git checkout develop
$
# Es aconsejable hacer "git pull" en este momento, antes de mezclar la rama, para traernos del repositorio los últimos cambios realizados en "develop".
$
$ git merge feature-captcha_en_registro
$ git branch -d feature-captcha_en_registro
$ git push origin develop
Podemos usar la rama «develop» como punto de partida del proyecto en nuestro entorno de pruebas y, si estamos satisfechos con el resultado, publicar una nueva versión del proyecto usando una rama temporal con el prefijo «release», seguida del nombre escogido para la nueva versión (puede ser un nombre en clave como los nombres de las versiones de Ubuntu o puede seguir un esquema de versionado como semver). Mezclaremos la rama «release» a la rama «master» y le pondremos una etiqueta para futuras referencias.
$ git checkout -b release-reckless_raccoon develop
$
# Aquí es donde modificaremos nuestro "CHANGELOG.md", incrementaremos el indicador de versión en nuestro "package.json", etc... También haremos "git commit" de esos cambios.
$
$ git checkout master
$ git merge release-reckless_raccoon
$ git tag -a reckless_raccoon
$
$ git checkout develop
$ git merge release-reckless_raccoon
$
$ git push origin develop master
$ git push origin --tags
$ git branch -d release-reckless_raccoon
Si se da la necesidad de realizar un cambio urgente, ya sea por un fallo de seguridad o un error grave en el código, crearemos una rama a partir de la rama «master» con el prefijo «hotfix» (por ejemplo, «hotfix-evitar_sql_inject»), aplicaremos los parches necesarios y mezclaremos la rama tanto en «master» como en «develop».
$ git checkout -b hotfix-evitar_sql_inject
$
# Aquí es donde aplicaremos el parche y haremos "git commit".
$ git checkout master
$ git merge hotfix-evitar_sql_inject
$ git tag -a reckless_raccoon_resurrected
$
$ git checkout develop
$ git merge hotfix-evitar_sql_inject
$
$ git push origin develop master
$ git push origin --tags
$ git branch -d hotfix-evitar_sql_inject
Resumiendo, las nuevas características se desarrollan en ramas basadas en «develop» y se integran en la misma. Tras realizar pruebas, «develop» se integra en «master». En caso de urgencia, creamos ramas de «hotfix» basadas en «master» y luego las integramos tanto en «master» como en «develop». Nunca subiremos directamente ni a «master» ni a «develop», sino que integramos cambios de otras ramas.
Todas estas operaciones mejorarán la manera en la que el equipo de desarrolladores trabaja sobre el proyecto. Nos ayudará a:
- Mantener una versión del proyecto siempre en buen estado (la rama «master»).
- Acumular cambios pendientes de probar de manera ordenada.
- Tener la posibilidad de diferenciar entre dos versiones y poder aplicar parches urgentes sin dificultad.
# Consejos adicionales
Automatización de pruebas y despliegues - Basándonos en la premisa establecida anteriormente de que vamos a considerar «master» la «versión estable» y «develop» la «versión pendiente de pruebas», podemos diseñar pipelines de CI/CD que ejecuten constantemente comprobaciones sobre el código añadido a estas ramas y, en caso de un resultado favorable de estas comprobaciones, desplegar nuestra aplicación de manera automatizada, ya sea al entorno de pruebas para que el equipo de QA pueda realizar comprobaciones adicionales, ya sea al entorno productivo.
Control de escritura - Si hemos implementado pipelines de CI/CD, probablemente no queremos que todos los integrantes de nuestro equipo de desarrollo puedan mezclar a las ramas de «develop» y «master». Probablemente queremos que los desarrolladores puedan subir código solo a sus ramas y que el lead developer, únicamente tras inspeccionar los parches realizados en dichas ramas, las mezcle a «develop».
Deshaciendo cambios - Inevitablemente, por muchas inspecciones que hagamos a las ramas de los desarrolladores y por muchas pruebas unitarias que ejecutemos, siempre se nos escapará algún fallo. Dependiendo de la gravedad y del tamaño del fallo se puede dar el caso de que no sea viable arreglar el fallo vía «hotfix». También se puede dar el caso de que simplemente queramos revertir la introducción de una novedad en el proyecto. En estos casos, lo que queremos hacer es revertir el conjunto de cambios que introdujeron dicho fallo o funcionalidad. Es decir, queremos revertir la integración de la rama desde la que mezclamos estos cambios. Esto puede ser una tarea difícil ya que, al mezclar una rama, lo que estamos haciendo en realidad es mezclar todos los commits de esa rama, y revertir dichos commits, de uno en uno, puede ser una tarea pesada. Para poder revertir fácilmente los cambios introducidos por una rama, es conveniente unir todos los commits de esa rama en un único commit mientras la mezclamos.
$ git merge --squash feature_captcha_en_registro
- Encontrando los errores - Algunas veces ocurren fallos que no terminamos de entender o cuya causa no nos queda muy clara. Para encontrar el origen de estos fallos, Git nos permite hacer una búsqueda binaria («git bisect») entre dos commits del historial de una rama (se suele elegir un commit en el que el fallo ocurre y otro commit en el que fallo no ocurre). Si no aplicamos lo aprendido del punto anterior («git merge -squash»), podremos encontrar el commit especifico que causa el fallo, pero no podremos revertir cambios con facilidad. Del mismo modo, si aplicamos lo aprendido del punto anterior, únicamente podremos saber qué rama introdujo el fallo, sin saber el commit exacto; pero podremos revertir cambios con mayor facilidad. La decisión de cuál de los dos puntos es más útil queda a elección del lector.
Referencia del contenido - https://nvie.com/posts/a-successful-git-branching-model/
¡Hola! ¿Te ha gustado el contenido de esta entrada? ¿Te ha aclarado las dudas que tenias sobre el tema? Si crees que podemos ayudarte a resolver los problemas técnicos en tu negocio o si crees que podemos trabajar juntos en tus proyectos o mejorarlos de alguna manera, escríbenos a [email protected].