El entorno de desarrollo perfecto con Docker
En esta entrada se explicará como usar Docker para conseguir un entorno de desarrollo óptimo y cómodo para trabajar. Se describirán algunos trucos que mejoran notablemente la rapidez con la que se opera con Docker y se darán algunos ejemplos prácticos sobre como Dockerizar entornos completos para la combinación de los lenguajes de programación y frameworks más comunes.
Nota: Esta entrada presupone que el lector ya cuenta con una instalación funcional de Docker, así como la herramienta docker-compose.
# "Múltiples entornos de desarrollo" como sinónimo de "problemas"
Cualquier desarrollador sabrá a lo que me refiero cuando digo que preparar un entorno de desarrollo para un nuevo proyecto es un proceso doloroso, en mayor o menor medida, dependiendo del proyecto. Y no solo eso, mantener en un estado óptimo dicho entorno también puede ser una tarea difícil, sobretodo si el entorno tiene que compartir la misma máquina física con otros entornos de desarrollo.
Todos hemos tenido que trabajar en un proyecto hecho con PHP 5 y MySQL 5, luego en otro hecho con PHP 7, luego en otro hecho con Python 2 y Postgres 9. Y para rematar, unos cuantos más, hechos con Python 3, PostgreSQL 10, Node 10, MongoDB 2, NGINX, Apache, al menos 5 o 6 versiones distintas de la misma librería usada en varios de los proyectos, etc.
Llega un momento en el que nuestro sistema operativo acaba al borde de la destrucción. Todos estos stacks empiezan a generar conflictos entre sí y actualizar cualquier componente del sistema, o incluso hacer alguna modificación, por muy pequeña que sea, es sinónimo de desconfigurar o dejar inutilizable alguno, varios o incluso todos los entornos de desarrollo.
Esto nos empuja a querer evitar actualizar los componentes de nuestro sistema e incluso el sistema en sí, lo cual evita que podamos aprovecharnos de las ventajas de las actualizaciones que no aplicamos y a la vez nos obliga a realizar nuestro trabajo en un sistema cada vez más desactualizado e inseguro.
Resumiendo, nuestro trabajo nos obliga a tener múltiples entornos de desarrollo, lo cual ha resultado ser una tarea difícil de realizar. ¿O tal vez no?
# Docker como solución
Desde hace muchos años existen decenas de herramientas que permiten encapsular de una manera u otra nuestros entornos de trabajo, permitiéndonos encapsularlos y manejarlos por separado, evitando así las desventajas previamente mencionadas. Sin embargo, todas estas herramientas tienen como desventaja su desorbitado uso de recursos (maquinas virtuales) o su innecesaria complejidad (contenedores "nativos", como por ejemplo LXC o OpenVZ).
Docker se presentó como una alternativa que solucionaba ambos problemas (a costa de hacer sacrificios en otros aspectos, tema que da para otro post) e implementaba una serie de características que terminarían por definirlo como la herramienta por excelencia para manejar contenedores. Usaremos todas estas ventajas para convertir Docker en una herramienta que nos permita tener todos nuestros entornos de desarrollo encapsulados. Es decir, conseguiremos un entorno de desarrollo (por proyecto) completamente funcional, autocontenido, de fácil manejo y replicación, con certificados SSL para poder simular por completo la puesta en marcha en producción del proyecto, etc.
# Conceptos necesarios
Para poder entender de manera correcta el resto de la entrada es necesario que antes definamos unos cuantos conceptos de Docker y de su funcionamiento. Esto nos ayudará a razonar mejor y con más claridad sobre las explicaciones que ofreceré, y sobretodo, nos permitirá a entender como crear nuestros propios entornos, basándonos en los ejemplos que pondré a continuación.
Nota: Definiré de manera parcialmente incorrecta algunas cosas y haré analogías extrañas, en pos de facilitar la lectura y la comprensión del funcionamiento de Docker.
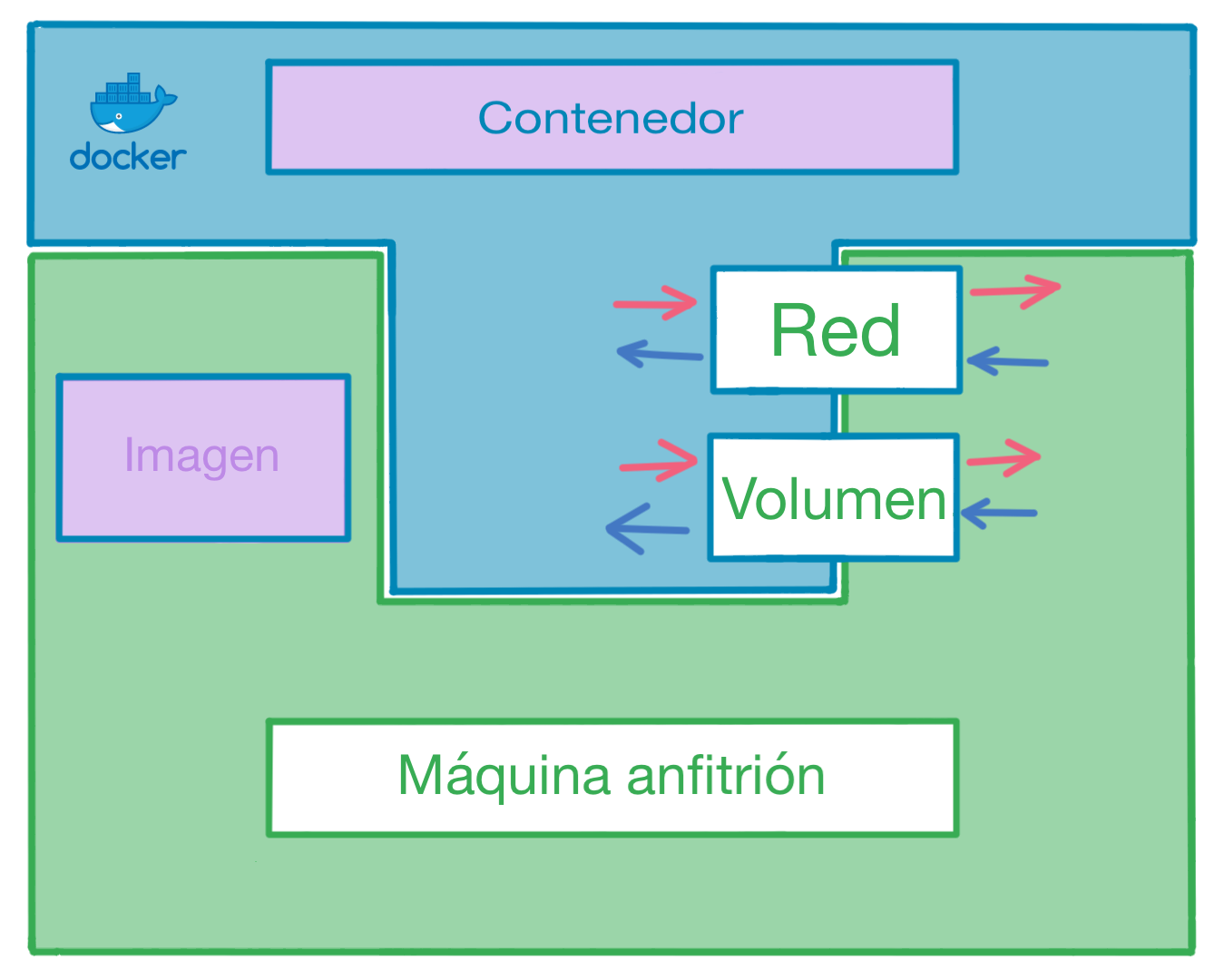
Docker - Es una herramienta que se queda a medio camino entre un chroot y una máquina virtual. Conseguimos una encapsulación mayor de procesos, de memoria, de disco duro y, en general, del entorno donde operan nuestras aplicaciones en comparación con chroot, pero no es una separación total, como lo que obtendríamos con una máquina virtual.
Contenedor (Container) - Podemos verlos como pequeños ordenadores o máquinas virtuales que se encargan de ejecutar nuestras aplicaciones contenerizadas. Cada contenedor ejecuta su propio "sistema operativo" y las aplicaciones que nosotros pongamos dentro, tiene su propio disco duro, su propia interfaz de red (incluida IP), etc.
Imagen (Image) - Una manera muy simple de entender lo que es una imagen es pensar que representa un LiveCD. Es lo que se usa para iniciar un contenedor.
Volumen (Volume) - Esto es, a efectos prácticos, el disco duro del contenedor. Debemos tener en cuenta que un volumen puede ser compartido entre nuestro contenedor y nuestro sistema operativo (es decir, ambos verán los mismos archivos en tiempo real) o privado, en cuyo caso únicamente el contenedor podrá ver el contenido del volumen.
Red (Network) - Para que los contenedores tengan una utilidad, queremos que sea posible acceder a las aplicaciones o servicios que se ejecutan en su interior. Lo más común es que dicho acceso se haga mediante red (ya sea exponiendo un servidor web, una API o cualquier otro servicio con capacidades de comunicación vía red). A veces también necesitamos que unos contenedores sean capaces de comunicarse vía red con otros contenedores (ejemplo: una aplicación accediendo a una instancia de Redis). Cabe destacar que Docker, además de permitirnos exponer los contenedores al contexto de nuestro sistema operativo, también es capaz de exponerlos únicamente entre ellos, mediante redes privadas, pero ocultándolos al contexto de nuestro sistema operativo.
# Una imagen vale más que mil entornos
Lo primero que debemos hacer es construir nuestra imagen, "grabando" en su interior todo lo que necesitamos para ejecutar nuestro proyecto. Aunque es posible construir una única imagen con todas las dependencias del aplicativo que queremos encapsular (el intérprete del lenguaje de programación que estemos usando, el servidor web, una base de datos, un almacén de acceso rápido, etc.), es una buena práctica separar cada uno de estos componentes en contenedores distintos o servicios.
Haciendo esta separación, en vez de hacer una imagen monolítica, podemos separar nuestros proyectos en distintos componentes y con eso conseguimos varias ventajas:
- Simplicidad
- Mayor encapsulación
- Reutilización de imágenes
- Fácil manejo de los contenedores
Nota: Cabe mencionar que separando nuestros servicios en múltiples imágenes tendremos que manejar múltiples contenedores. Mas adelante en esta entrada veremos que esto no supone mayor esfuerzo ni mayor complejidad, sino justo lo contrario.
Nota: Empezaré con un ejemplo orientado a entornos de desarrollo con Python y Django, pero al final de la entrada dejaré más ejemplos orientados a otros lenguajes de programación y frameworks.
Nota: Todos los archivos están disponibles en un repositorio de Github.
Para construir nuestra primera imagen debemos disponer de un archivo al que llamaremos Dockerfile (es recomendable hacerlo dentro de una carpeta de pruebas). Mediante este archivo podemos dar órdenes a Docker sobre como debe construir nuestra imagen. Podemos copiar archivos desde el contexto de nuestro sistema operativo a la imagen, ejecutar comandos dentro de la misma o establecer varios parámetros que explicaré en los siguientes párrafos.
Dockerfile
FROM python:3.6.4-stretch
WORKDIR /app
COPY docker/system-requirements.txt /srv/system-requirements.txt
RUN apt-get -qq update && \
apt-get -qq install ca-certificates gettext locales libsasl2-dev python-dev libpq-dev netcat && \
rm -rf /var/lib/apt/lists/*
RUN echo "en_US.UTF-8 UTF-8" > /etc/locale.gen
RUN echo "es_ES.UTF-8 UTF-8" >> /etc/locale.gen
RUN ln -fs /usr/share/zoneinfo/CET /etc/localtime
COPY src/requirements.txt /app/requirements.txt
RUN pip install -U pip setuptools wheel && \
pip install -r /app/requirements.txt
COPY docker/entrypoint.sh /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]
CMD ["bash"]
A priori puede parecer que falta algo, ya que es sospechoso que tan pocas lineas de código puedan crear un entorno completo de desarrollo. Sin embargo, no es el caso. El truco está en la primera línea, donde usamos la palabra clave FROM. Esta palabra indica a Docker que debe construir nuestra imagen usando como base la imagen de python, en su versión 3.6.4, basada en debian stretch. Es decir, en vez de partir de un lienzo en blanco, partimos de un Debian Stretch sobre el cual ya se ha instalado Python 3.6.4.
Docker cuenta con un repositorio público donde es posible subir imágenes. Normalmente, ahí podemos encontrar imágenes oficiales de los stacks de desarrollo más comunes, con un mantenimiento adecuado y un ritmo de actualizaciones muy bueno. Aprovechándonos de este repositorio, podemos construir imágenes complejas en pocas lineas de código.
Volviendo a la explicación, las siguientes lineas se encargan de establecer la ruta desde la que se ejecutarán (de manera predeterminada) los comandos dentro de nuestro contenedor; configurar el idioma y la zona horaria; copiar el archivo que especifica las dependencias de nuestro proyecto de Django (requirements.txt) y de instalarlas con pip. Con esto conseguimos que nuestra imagen tenga todas las librerías y dependencias necesarias para ejecutar nuestro proyecto.
Nota: Es importante mencionar que el comando COPY no copiará archivos o carpetas que coincidan con alguno de los patrones definidos en el archivo .dockerignore. Esto es muy importante, ya que nos permite excluir archivos innecesarios y obtener imágenes más pequeñas.
Por último, copiamos un script que nos servirá de ENTRYPOINT (el comando por defecto). Cuando iniciamos un contenedor, dicho contenedor debe ejecutar un programa. Mientras dicho programa siga ejecutándose, el contenedor permanece operativo. Si el programa termina por cualquier motivo, el contenedor se apaga. En este caso nuestro programa es un script y lo especificamos mediante el uso de ENTRYPOINT, mientras que nuestro comando o CMD (que actúa como parámetro de nuestro ENTRYPOINT) es bash.
En definitiva, el comando completo que se ejecutará cuando iniciemos nuestro contenedor (sin parámetros) será ./entrypoint.sh bash. Si usáramos parámetros para iniciar nuestro contenedor, el comando que se ejecutaría sería ./entrypoint.sh parámetros-que-hemos-usado-para-iniciar-el-contenedor.
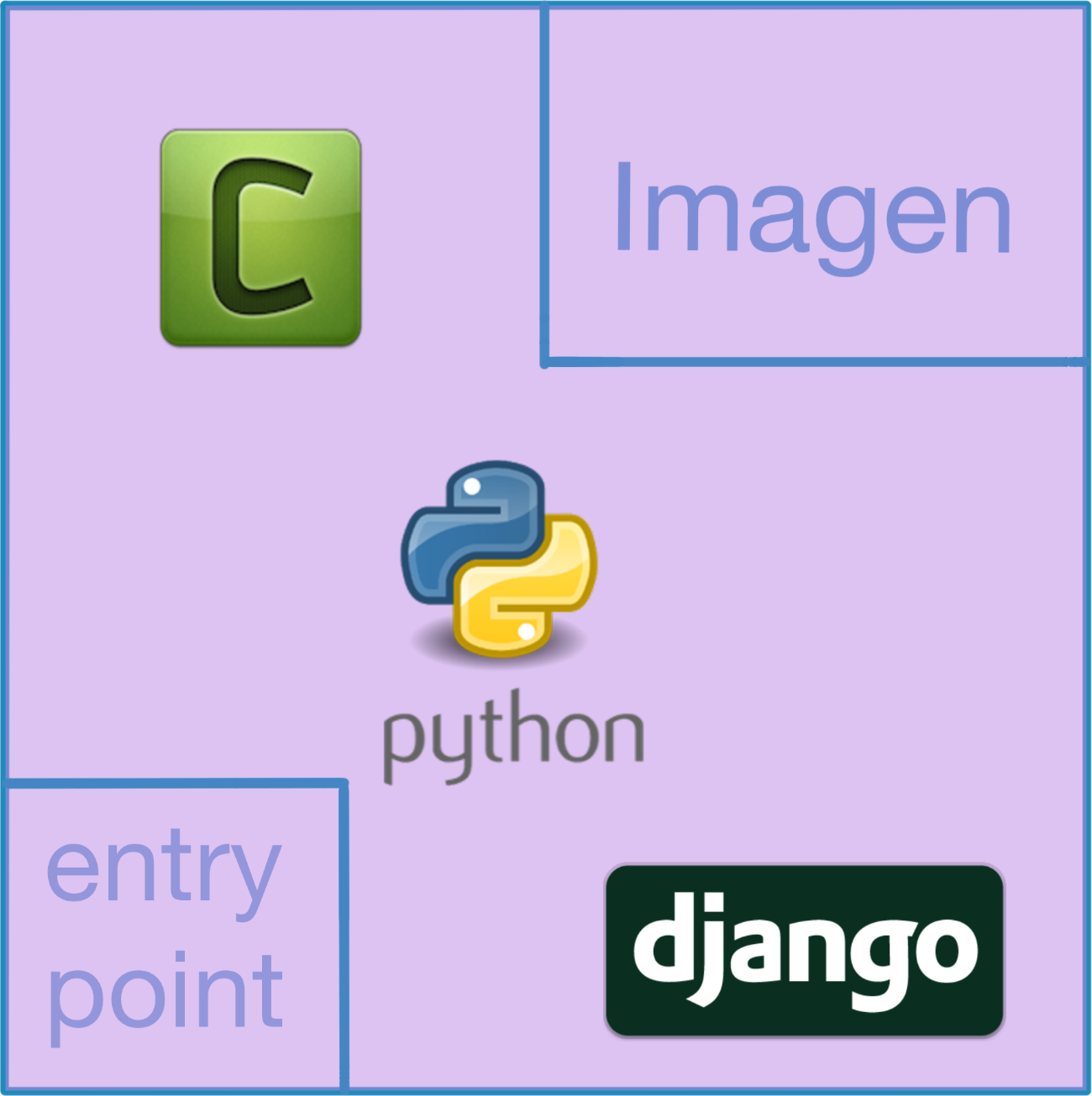
Nota: Si el ENTRYPOINT no estuviese especificado, podríamos especificar mediante el CMD tanto el programa de inicio como sus parámetros. Al estar el ENTRYPOINT definido, el comando o CMD se convierte en parámetros de nuestro programa.
Para que terminemos de entender el ENTRYPOINT y el CMD, debemos examinar el entrypoint.sh.
entrypoint.sh
#!/bin/bash
set -e
function wait_service {
while ! nc -z $1 $2; do
sleep 1
done
}
case $1 in
run-migrations)
echo "--> Applying migrations"
wait_service $DATABASE_HOST $DATABASE_PORT
exec python manage.py migrate --noinput
;;
run-runserver)
echo "--> Starting Django's server"
wait_service $DATABASE_HOST $DATABASE_PORT
exec python manage.py runserver 0.0.0.0:8000
;;
run-tests)
echo "--> Starting Django's test framework"
wait_service $DATABASE_HOST $DATABASE_PORT
exec python manage.py test
;;
run-celery)
echo "--> Starting Celery queue"
wait_service $REDIS_HOST $REDIS_PORT
exec celery worker -A main -l info
;;
run-celery-flower)
echo "--> Starting Celery flower"
wait_service $REDIS_HOST $REDIS_PORT
exec celery flower -A main --port=5555
;;
run-celery-beat)
echo "--> Starting Celery beat"
wait_service $REDIS_HOST $REDIS_PORT
exec celery beat -A main -l info
;;
*)
exec "$@"
;;
esac
Como ya hemos dicho antes, nuestro contenedor ejecutará este script y se mantendrá activo mientras el script no termine su ejecución. Por otro lado, el Dockerfile define que el comando (parámetro en este caso, ya que hemos definido un ENTRYPOINT) por defecto es la cadena de texto bash. Si analizamos el script, podemos ver que tiene definida una función, que ignoraremos por el momento, y un case, que evalúa el primer parámetro ($1) que ha recibido. Cuando el contenedor se ejecuta sin parámetros, el parámetro por defecto que usa es bash, así que el flujo de ejecución del script no entra en ninguno de los casos definidos, sino que ejecuta el caso por defecto (*)).
El comando exec "$@" ejecuta nuestros parámetros como si fuesen un comando, con lo cual conseguimos que el script ejecute cualquier comando que queramos. Mas adelante veremos como este truco nos va a resultar muy útil para poder definir múltiples comportamientos de una misma imagen de Docker.
# Usando las imágenes con contenedores
Ahora que ya tenemos algo de teoría sobre imágenes de Docker, vamos a ver como podemos usarlas. Como ya hemos dicho previamente, una imagen sirve como disco de arranque de un contenedor. También hemos mencionado que es una buena práctica separar cada uno de los componentes de nuestros proyectos en servicios. Podríamos crear un Dockerfile para cada servicio y luego crear imágenes a partir de cada Dockerfile y ejecutar tantos contenedores como imágenes hayamos creado, pero existen herramientas que ya están pensadas para ahorrarnos ese trabajo y permitirnos manejar los distintos servicios de un mismo proyecto de manera cómoda: docker-compose.
Siguiendo con el ejemplo de un entorno de desarrollo adaptado a Python y Django, nuestros servicios podrían ser NGINX, el intérprete de Python, los varios componentes de Celery, Redis y PostgreSQL. Si nos fijamos en el archivo docker-compose.yml veremos exactamente esto, la definición de varios servicios.
Veamos cada una de las partes del archivo:
versión: "3.2"
Aquí definimos que versión de las especificaciones de docker-compose va a usar nuestro archivo. Cada versión implementa nuevas características, por lo que nos interesa mantenernos al tanto de las novedades y actualizar nuestros proyectos si lo vemos oportuno.
services:
nginx-proxy:
image: jwilder/nginx-proxy
container_name: proyecto-django-nginx-proxy
ports:
- "80:80"
- "443:443"
networks:
- proyecto-django-internal
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
- ./certs:/etc/nginx/certs
depends_on:
- proyecto-django
Aquí definimos la sección de "servicios" y nuestro primer servicio: un servidor web usando la imagen jwilder/nginx-proxy. A mayores, definimos el nombre del contenedor que va a ejecutar esta imagen, los puertos que expone el contenedor a nuestro sistema, la red privada de la que forma parte, los volúmenes (en este caso compartidos) entre nuestro sistema y el contenedor y, por último, los contenedores de los que depende.
Quizás lo más curioso de este servicio sea uno de los volúmenes que usa. Sin entrar en demasiados detalles técnicos, exponer el /var/run/docker.sock al contenedor hará que sea capaz de detectar las peticiones web lanzadas desde nuestro sistema e interceptarlos.
Nota: Si estás usando Windows, el primero de los volúmenes deberá ser - //var/run/docker.sock:/tmp/docker.sock:ro (doble // al principio).
proyecto-django:
build: .
container_name: proyecto-django
env_file:
- ./src/.env
command: ["run-runserver"]
stdin_open: true
tty: true
networks:
- proyecto-django-internal
ports:
- 8080:8000
environment:
- VIRTUAL_HOST=proyecto-django.dev
- VIRTUAL_PORT=8000
depends_on:
- redis
- postgres
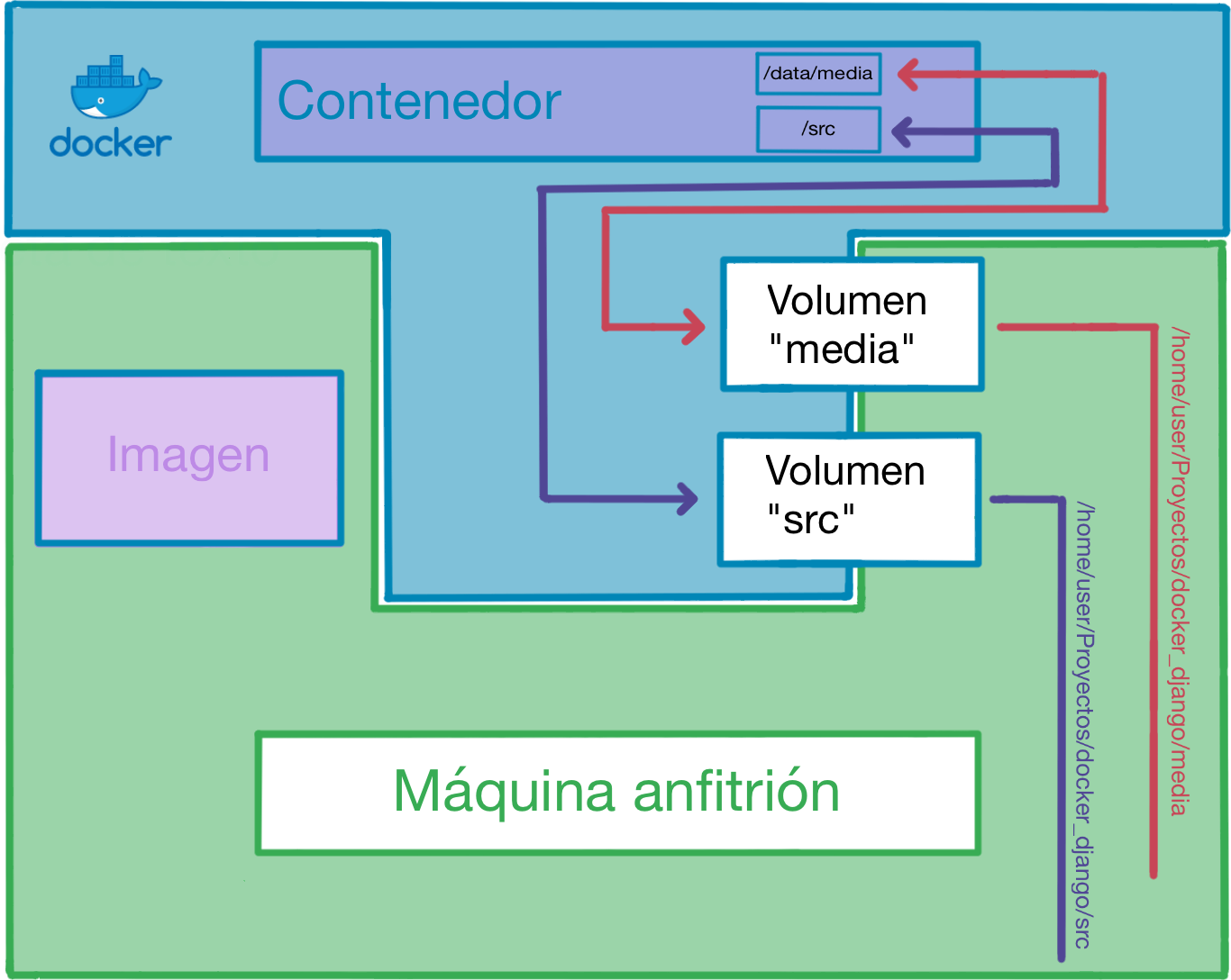
volumes:
- ./src:/app/
- ./media:/data/media
Aquí definimos el servicio que se encargará de ejecutar nuestro proyecto. Lo primero a destacar es que aquí no estamos usando la instrucción image (como en el anterior servicio), sino que estamos usando la instrucción build, lo cual hace que docker-compose busque un Dockerfile en el directorio especificado (. en este caso) y use la imagen que se construirá a partir de dicho archivo.
La segunda cosa a destacar es que estamos inyectando variables de entorno (leídas desde el archivo src/.env) dentro del contenedor usando la instrucción env_file. Esto nos permite configurar parámetros en el código de nuestra aplicación de Django.
Nota: Si no estás completamente seguro de por qué esto es útil, te invitamos a leer el punto relacionado con la "Configuración" en nuestra entrada sobre las aplicaciones de 12 factores.
Tercero, el uso de la instrucción command. El valor que definimos aquí se usará como sustituto del comando CMD en la imagen del contenedor. En este caso, estamos usando la imagen que hemos construido nosotros mismos usando nuestro Dockerfile. Es decir, cuando este contenedor se inicie, el comando que se ejecutará será ./entrypoint.sh run-runserver, en vez de ./entrypoint.sh bash. Si volvemos a mirar el código del entrypoint.sh, veremos que existe un case para run-runserver, que hará uso de la función wait_service para asegurarse de que nuestro servicio de la base de datos está operativo y después ejecutará el servidor de Django en el puerto 8000.
La cuarta cosa a destacar es el uso de los comandos stdin_open y tty. Estos comandos se encargarán de brindarnos una TTY capaz de recibir input (muy útil para, por ejemplo, poder manejar un depurador, como pdb, que se ejecuta dentro de nuestro contenedor).
Otra cosa importante que debemos mencionar es que, además de haber inyectado variables de entorno usando el env_file, estamos inyectando 2 variables de entorno a mayores. La primera es VIRTUAL_HOST y nos permite definir el dominio a usar para acceder a nuestro contenedor desde nuestro sistema, todo esto pasando por el servicio de NGINX. La segunda es VIRTUAL_PORT y le permite saber al servicio de NGINX a que puerto del contenedor conectarse (nuestra aplicación de Django estará escuchando en el puerto 8000 por defecto). Debemos aclarar que podríamos conectarnos directamente a nuestro contenedor de Django usando http://localhost:8000 en el navegador de nuestro sistema, pero pasar por NGINX nos permitirá usar certificados de SSL, lo cual puede resultarnos muy útil a la hora de depurar aplicaciones que dependen del uso obligatorio de HTTPS.
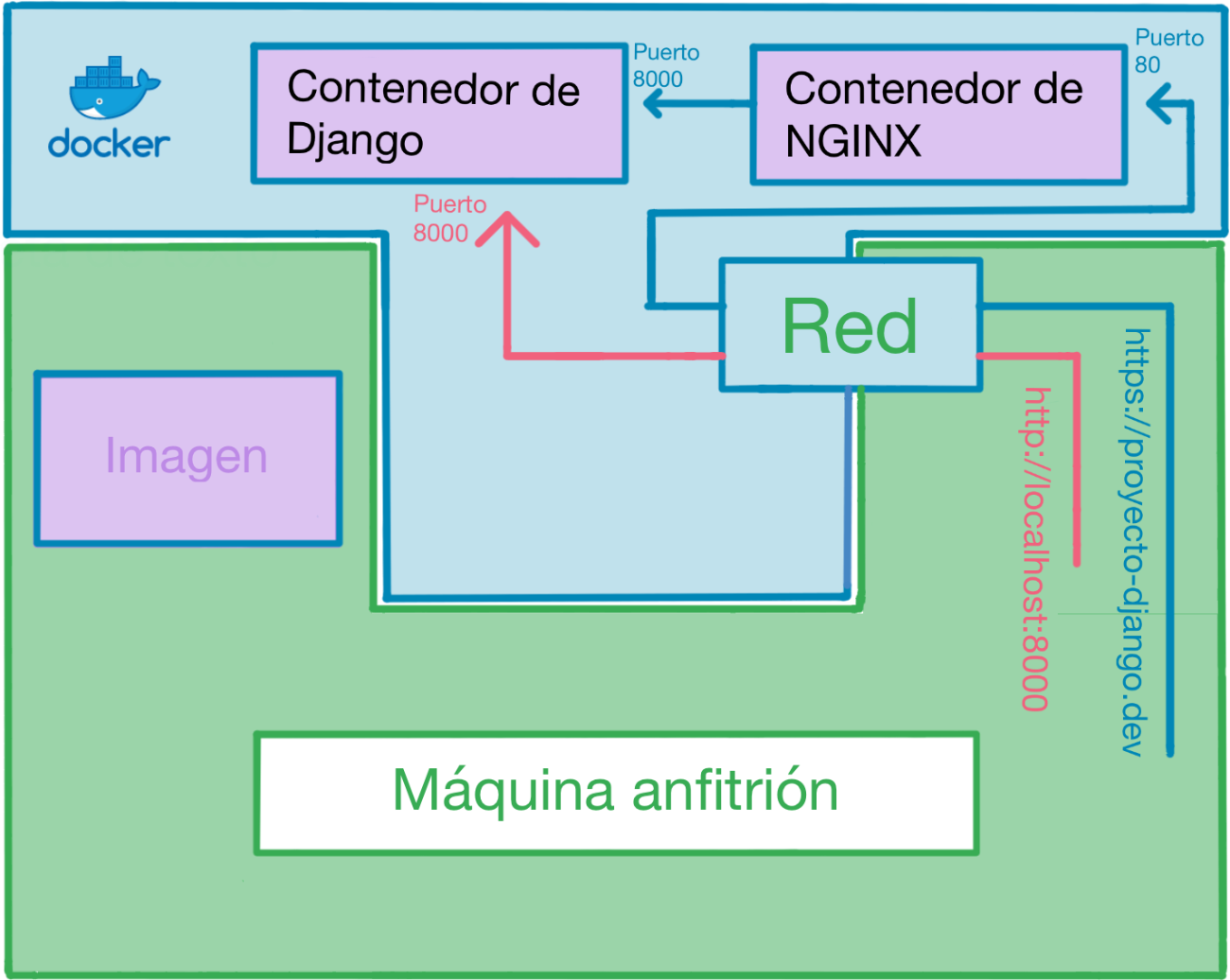
Por último, mencionar que este contenedor usará 2 volúmenes compartidos con el sistema. El primero es la carpeta src, cuyo contenido será visible desde la carpeta /app dentro de nuestro contenedor. Si volvemos a mirar nuestro Dockerfile, nos daremos cuenta que el WORKDIR está puesto a /app, lo cual significa que todos los comandos que ejecutemos dentro del contenedor (sin habernos cambiado de directorio a propósito), serán ejecutados directamente sobre el contenido de nuestra carpeta src.
El segundo volumen es la carpeta media, que será visible desde la carpeta /data/media dentro de nuestro contenedor. Este segundo volumen se ha incluido únicamente como ejemplo para el uso de múltiples volúmenes en caso de ser necesarios.
celery:
build: .
container_name: proyecto-django-celery
env_file:
- ./src/.env
command: ["run-celery"]
networks:
- proyecto-django-internal
depends_on:
- redis
- celery-beat
- celery-flower
volumes:
- ./src:/app/
- ./media:/data/media
celery-flower:
build: .
container_name: proyecto-django-celery-flower
env_file:
- ./src/.env
command: ["run-celery-flower"]
networks:
- proyecto-django-internal
ports:
- 5555:5555
depends_on:
- redis
volumes:
- ./src:/app/
- ./media:/data/media
celery-beat:
build: .
container_name: proyecto-django-celery-beat
env_file:
- ./src/.env
command: ["run-celery-beat"]
networks:
- proyecto-django-internal
depends_on:
- redis
volumes:
- ./src:/app/
- ./media:/data/media
Definimos los distintos componentes de Celery (Celery, Beat y Flower). Las definiciones son prácticamente idénticas, siendo la única diferencia el parámetro que cada contenedor usará con el entrypoint.sh.
postgres:
image: postgres:9.6.6-alpine
container_name: proyecto-django-postgres
env_file:
- ./src/.env
networks:
- proyecto-django-internal
volumes:
- ./data/postgres:/var/lib/postgresql/data
redis:
image: redis:3.2.8-alpine
container_name: proyecto-django-redis
volumes:
- ./data/redis:/data
networks:
- proyecto-django-internal
Definimos los contenedores de PostgreSQL y Redis. Cabe mencionar que, si nos fijamos en la documentación de la imagen de PostgreSQL, veremos que la imagen está diseñada de tal manera que en la primera ejecución de cada contenedor que haga uso de la misma, se creará una base de datos y un usuarios con su correspondiente contraseña a partir de varias variables de entorno (POSTGRES_DB, POSTGRES_USER y POSTGRES_PASSWORD). Nosotros hemos definido dichas variables en el archivo .env, por lo que no tendremos que crear a mano bases de datos ni usuarios.
networks:
proyecto-django-internal: {}
Por último, definimos la red privada que usarán nuestros contenedores.
Debemos mencionar por encima los servicios que hemos definido en el archivo docker-compose.tests.yml. Son idénticos a los servicios que ya hemos visto, con la excepción que estamos usando 2 archivos con la instrucción env_file. Esto hará que las variables del segundo archivo sobrescriban las variables con las que coincidan del primer archivo.
Los servicios definidos en el archivo docker-compose.tools.yml serán descritos con más detalle al final de la entrada.
# Usando docker-compose (con make)
Ya sabemos lo que es una imagen, sabemos lo que es un servicio, sabemos cómo definir múltiples servicios dentro de un mismo proyecto, pero ¿cómo hacemos uso de toda esta teoría? Ya hemos mencionado previamente la herramienta docker-compose. Esta será la herramienta que nos permita hacer uso de nuestros archivos docker-compose.*.yml.
Dado que hemos separado nuestros servicios en varios archivos, lo primero que debemos tener en cuenta es la manera de "componer" o "unir" estos archivos. Podemos usar el parámetro -f para especificar todos los archivos que queremos que docker-compose una por nosotros. En caso de que algún servicio esté duplicado en varios .yml, las instrucciones se mezclarán (en caso de almacenar múltiples valores) o se sobrescribirán por la definición del último archivo (en caso de ser una instrucción con un único valor posible).
Por ejemplo, para iniciar nuestro contenedor de NGNIX y todas sus dependencias, podríamos usar el comando
docker-compose -f docker-compose.yml -f docker-compose.databases.yml up -d nginx-proxy
Acordarse de incluir todos los archivos .yml, los nombres de los contenedores y los varios comandos de docker-compose es una tarea pesada, por eso hemos incluido un archivo que nos servirá de mucha ayuda: Makefile. En dicho archivo hemos definido varios targets que podremos usar para hacer prácticamente todas las operaciones que podríamos necesitar. Simplemente necesitamos ejecutar el comando make (debemos tener instalada dicha herramienta en nuestro sistema) seguido del nombre del target.
Targets definidos:
start- Inicia el contenedor de NGINX y todas sus dependencias (el contenedor de Python/Django, los componentes de Celery, Redis y PostgreSQL). A efectos prácticos, vamos a usar estetargetpara ejecutar nuestro proyecto. Tras iniciar los contenedores, se ejecutará eltargetlogs. La combinación de teclasCTRL + Cno detendrá los contenedores, solo parará la salida delogspor consola.stop- Detiene todos los contenedores.restart- Reinicia todos los contenedores.delete- Borra todos los contenedores (no afecta a las imágenes).migrate- Ejecuta el contenedor de Python/Django con el parámetrorun-migrations. Haciendo un repaso rápido al archivoentrypoint.sh, vemos que ese parámetro ejecuta las migraciones de Django.tests- Ejecuta el contenedorproyecto-django-testsdefinido endocker-compose.tests.yml, así como sus dependencias. A efectos prácticos, vamos a usar estetargetpara ejecutar nuestras pruebas unitarias. Cabe mencionar que el contenedor de tests usa servicios de Redis y PostgreSQL distintos al contenedorproyecto-django.build- Construye todas las imágenes necesarias para ejecutar el proyecto. En este caso, se construirá una única imagen a partir del archivoDockerfiley luego se reusará en los distintos contenedores que usan la instrucciónbuild.build-nocache- Ídem quebuild, pero sin hacer uso de cache.status- Lista el estado de todos los contenedores.bash- Nos permite abrir rápidamente una terminal en el contenedorproyecto-django.shell- Ídem quebash, pero directamente entramos en la consola de Django.attach- Cuando ejecutamos un contenedor, podemos ver la salida por consola, pero no podemos interactuar con esa salida. Cuando nos "acoplamos" (attach) al TTY de un contenedor (que tenga las opcionesstdin_openyttyhabilitadas), podemos interactuar con su salida por consola.logs- Muestra la salida por consola de cada uno de los contenedores. Deberemos usar esto con frecuencia, ya que esta es la manera más rápida y cómoda de ver que está ocurriendo con cada uno de nuestros contenedores.delete_images- Borra todas las imágenes.backup- Hace una copia de seguridad de la base de datos en la carpetadata/backup.restore- Restaura una copia de seguridad de la base de datos de la carpetadata/backup.certs- Crea los certificados SSL autofirmados que usará nuestro contenedor de NGINX. Debemos tener la herramientamkcertinstalada.install_certs- Instala el certificado raíz en nuestro sistema. De esta manera, todos los certificados que generemos usando eltargetscertsserán validos a ojos de nuestro sistema.
# 3, 2, 1... ¡Despegamos!
¡Basta de teoría! ¡Vamos a ejecutar esto de una vez!
Hay 3 pasos que debemos realizar una única vez.
Añadimos el dominio
proyecto-django.deva nuestro/etc/hosts(o equivalente en Windows) y lo apuntamos a127.0.0.1.Ejecutamos
make install_certspara instalar el certificado raíz en nuestro sistema.Ejecutamos
make certspara generar unos certificados que usaremos en nuestro proyecto.
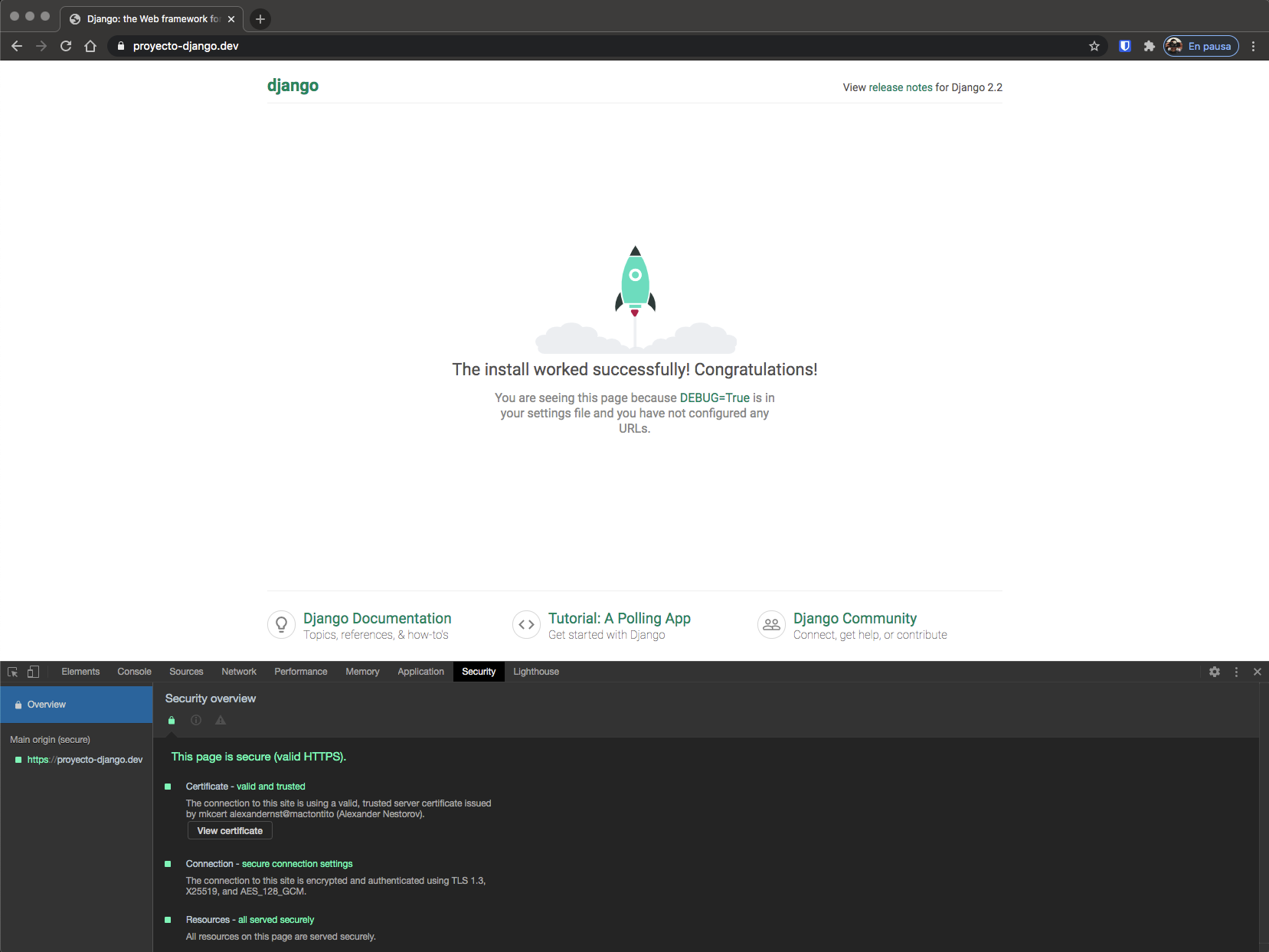
¡Ahora ya estamos listos para ejecutar nuestro proyecto!
Ejecutamos make start y visitamos https://proyecto-django.dev en nuestro navegador.
# Consejos y explicaciones adicionales
Nos hemos dejado un par de cosas sin explicar. Si quieres comprender todos los detalles del entrypoint.sh y los servicios de backup y restore, ¡sigue leyendo!
# La función de wait_service
Hay una gran diferencia entre iniciar un contenedor e iniciar una aplicación dentro del contenedor. Lo primero ocurre tan rápido como Docker sea capaz de iniciar un contenedor, lo segundo depende de la aplicación en sí. Cuando configuramos los distintos contenedores y sus dependencias, hay ciertos límites que Docker no puede sobrepasar. Por ejemplo, puede iniciar un contenedor que esté marcado como dependencia de otro contenedor, pero no puede hacer que el programa que se está ejecutando en el primer contenedor se quede "esperando" a que el programa del segundo contenedor esté disponible. Por esa razón nuestro entrypoint.sh tiene una función llamada wait_service.
Dicha función no es más que un netcat dentro de un bucle, intentando conectarse a un destino y un puerto. Cuando netcat consigue conectarse, la ejecución de nuestro entrypoint.sh continúa.
Veámoslo con un ejemplo práctico:
function wait_service {
while ! nc -z $1 $2; do #<-----------------
sleep 1 # | |
done # | |
} # | |
# | |
# | |
wait_service $REDIS_HOST $REDIS_PORT # ---- |
wait_service $DATABASE_HOST $DATABASE_PORT # ---
# Esta línea no se ejecutará hasta que PostgreSQL y Redis estén disponibles
exec python manage.py runserver 0.0.0.0:8000
Los valores de $REDIS_HOST, $REDIS_PORT, $DATABASE_HOST y $DATABASE_PORT vienen de las variables de entorno, las cuales a su vez vienen de nuestro archivo .env, que ha sido inyectado en cada uno de nuestros contenedores por Docker.
Pero si nos fijamos en nuestro archivo .env, veremos que REDIS_HOST y DATABASE_HOST no son IPs, sino cadenas de texto:
DATABASE_HOST=postgres
REDIS_HOST=redis
Lo cual nos lleva al siguiente punto.
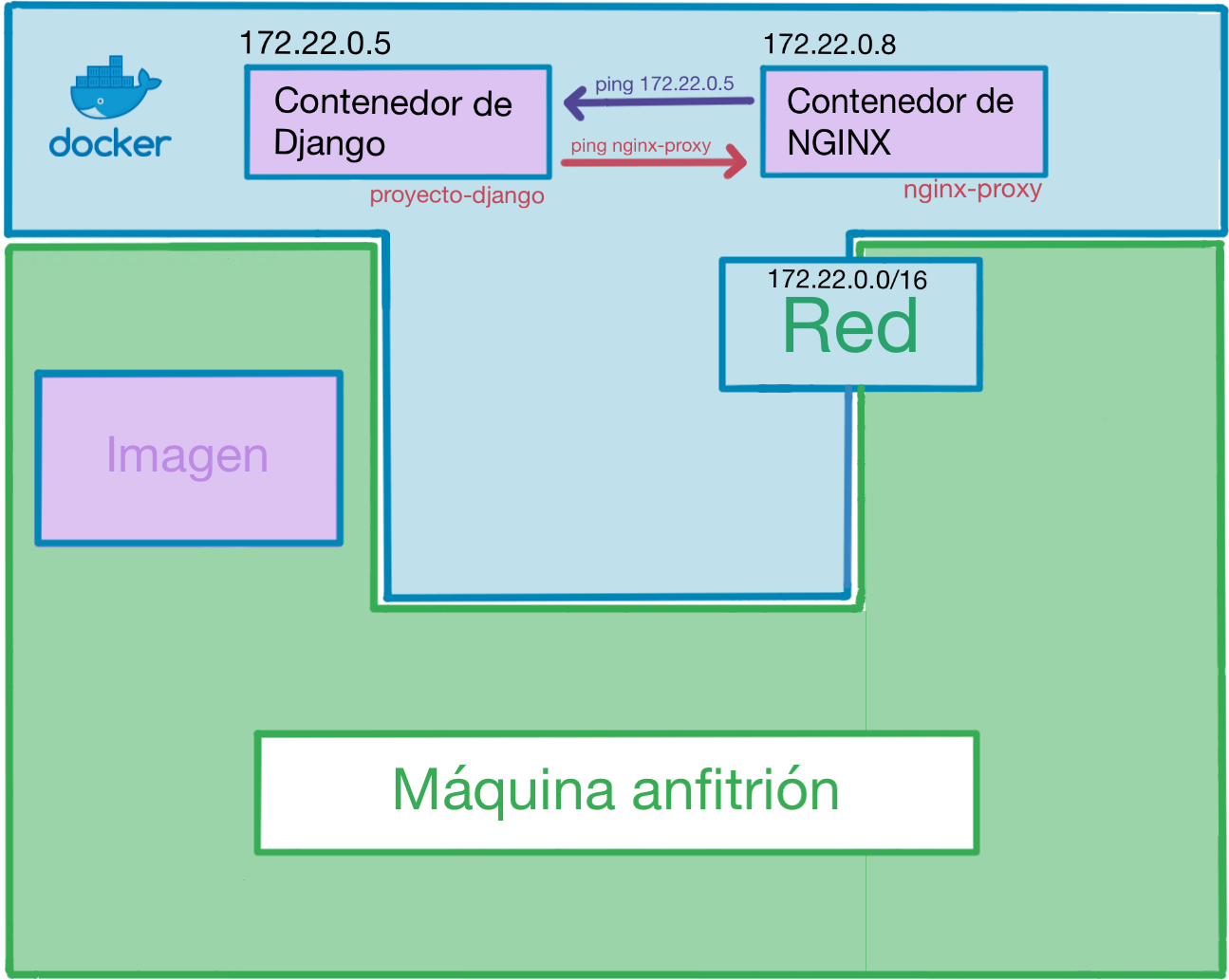
# Visibilidad de contenedores dentro de su red
Cada contenedor tiene su IP privada dentro de la red que hemos definido. Pero, a mayores, Docker es capaz de resolver las IPs de nuestros contenedores usando sus nombres. Si volvemos a fijarnos en el archivo docker-compose.yml veremos que los contenedores de PostgreSQL y Redis se llaman, respectivamente, postgres y redis. Esos nombres son los que usamos con la función wait_service.
# Servicios de backup y restore
Hay un archivo cuyo contenido no hemos explicado todavía: docker-compose.tools.yml. En este archivo hemos definido 2 servicios que nos pueden ser de gran ayuda durante el proceso de desarrollo: backup y restore. Como sus propios nombres indican, sirven para realizar y restaurar copias de seguridad de la base de datos. Si los analizamos detenidamente, veremos que la única diferencia que tienen con el resto de contenedores que hemos visto es el command.
Ambos tienen un command multilínea que invoca el intérprete bash pasándole una cadena de ordenes. El contenedor de backup ejecuta el comando pg_dump y escribe el resultado en el directorio /backup que está vinculado a data/backup en el contexto de nuestro sistema. El contenedor restore ejecuta el comando psql, leyendo del mismo directorio.
En ambos casos, lo que ocurre en realidad es que estamos pasando toda la cadena de texto que lleva el command como parámetro al contenedor. El contenedor le pasa esa cadena de texto al entrypoint.sh, el cual a su vez ejecuta el caso por defecto, dando lugar a exec "$@". Es decir, estamos usando exec "$@" para poder ejecutar código aleatorio en nuestra imagen, en vez de tener que definir casos adicionales por cada función que queremos añadir a mayores.
# Más ejemplos
Hemos cubierto muchos conceptos, pero sabemos que los ejemplos prácticos son los que mayor ayuda ofrecen, por eso hemos preparado varios ejemplos más.
# Notas finales
Quiero dar las gracias a Oscar M. Lage por haberme animado a escribir este post, por haberme ayudado con las pruebas de los ejemplos y por haber realizado una revisión de este post. ¡Muchas gracias!
¡Hola! ¿Te ha gustado el contenido de esta entrada? ¿Te ha aclarado las dudas que tenias sobre el tema? Si crees que podemos ayudarte a resolver los problemas técnicos en tu negocio o si crees que podemos trabajar juntos en tus proyectos o mejorarlos de alguna manera, escríbenos a [email protected].